# 项目开发
# 开发环境
- MySQL 8.0
- Redis 7.0
- Elasticsearch 8.2.0(选装)
- RabbitMQ 3.10.2(选装)
- XXL-JOB 2.3.1(选装)
- JDK 17
- Maven 3.8.5
- IntelliJ IDEA 2021.3
- Node 16.14
# IDEA 插件安装
使用 IntelliJ IDEA 开发的同学建议安装以下插件:
必装
选装
Translation - 翻译插件
Maven Helper - 分析 Maven 依赖,解决 Jar 冲突
EasyYapi - 帮助你导出文件中的 API 到
yapi/postman/markdown或发起文件中的 API 请求Codota - 代码智能提示
Search In Repository - 搜索 Maven 或者 NPM 的依赖信息
CamelCase - 多种命名格式(下划线、驼峰等)之间切换
Auto filling Java call arguments - 自动补全调用函数的参数
GenerateO2O - 生成一个对象并自动填充另一个对象的值
GenerateAllSetter - 一键调用一个对象的所有的set方法
SequenceDiagram - 调用链路自动生成时序图
Rainbow Brackets - 让你的括号变成不一样的颜色,防止错乱括号
HighlightBracketPair - 括号开始和结尾,高亮显示
Grep Console - 控制台日志 高亮
Key promoter X - 鼠标操作的快捷键提示
CodeGlance - 缩略图
VisualGC - 实时垃圾回收监控
arthas idea - java 在线诊断工具
Alibaba Cloud Toolkit - 通过图形配置的方式连接到云端部署环境并将应用程序快速部署到云端
上班摸鱼
Leetcode Editor IDEA 在线刷题
GIdeaBrowser IDEA 内嵌 Web 浏览器
# 项目初始化
我们使用 Spring Initializr 来初始化我们的项目。
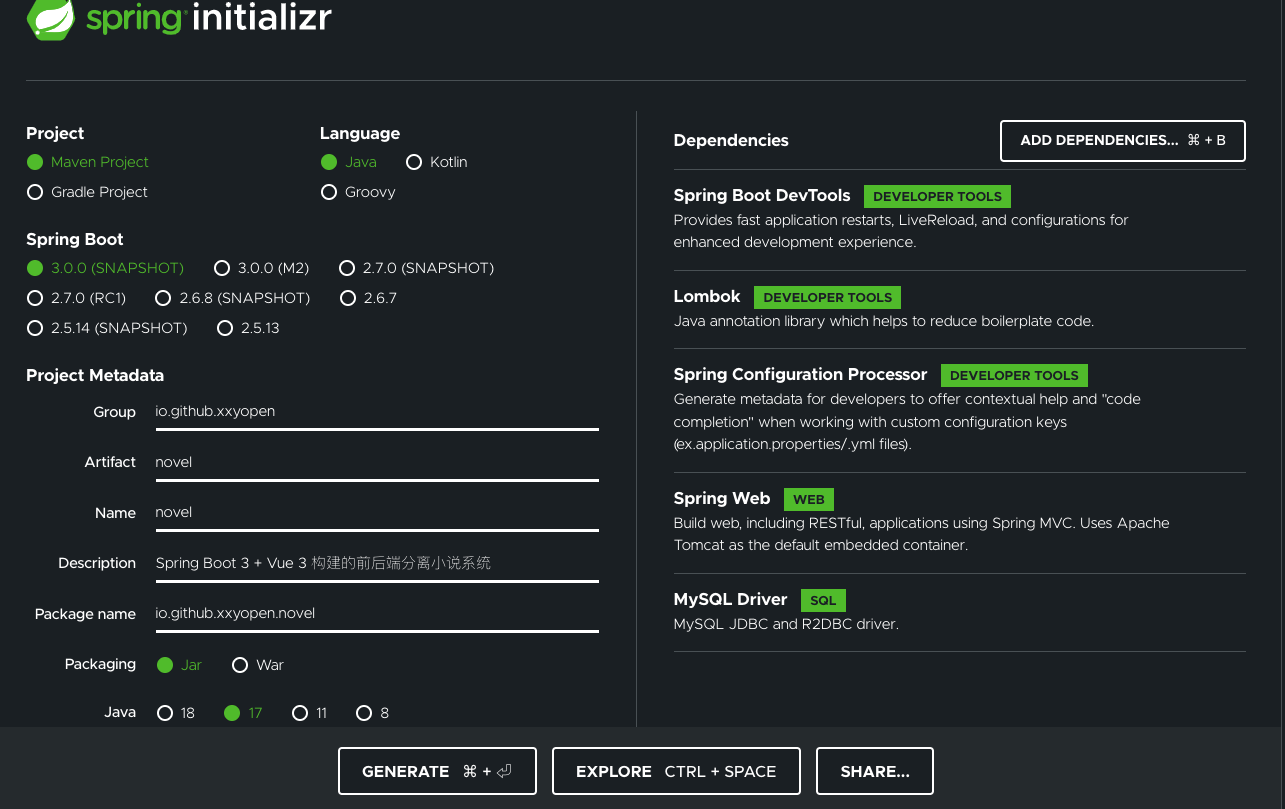
操作步骤如下:
导航到 Spring Initializr (opens new window)。该服务引入应用程序所需的所有依赖项,并自动完成大部分设置。
选择 Gradle 或 Maven 以及要使用的语言。本项目选择 Maven 和 Java。
选择 Spring Boot 的版本。本项目选择 3.0.0-SNAPSHOT 版本。
填写项目元数据。本项目选择 Java 17 版本。
单击 ADD DEPENDENCIES 并选择项目依赖项。本项目选择的依赖如上图所示。
单击 GENERATE,下载生成的 ZIP 文件,该文件是根据我们的选择来配置的 Spring Boot 应用程序存档。
解压 ZIP 文件后导入我们的 IDE 中即可。
注:如果我们的 IDE 具有 Spring Initializr 集成,可以直接从 IDE 中完成此过程
# 项目配置和框架集成
# 包结构创建
在项目 src/main/java 下面创建如下的包结构:
io
+- github
+- xxyopen
+- novel
+- NovelApplication.java -- 项目启动类
|
+- core -- 项目核心模块,包括各种工具、配置和常量等
| +- common -- 业务无关的通用模块
| | +- exception -- 通用异常处理
| | +- constant -- 通用常量
| | +- req -- 通用请求数据格式封装,例如分页请求数据
| | +- resp -- 接口响应工具及响应数据格式封装
| | +- util -- 通用工具
| |
| +- auth -- 用户认证授权相关
| +- config -- 业务相关配置
| +- constant -- 业务相关常量
| +- filter -- 过滤器
| +- interceptor -- 拦截器
| +- task -- 定时任务
| +- util -- 业务相关工具
| +- wrapper -- 装饰器
|
+- dto -- 数据传输对象,包括对各种 Http 请求和响应数据的封装
| +- req -- Http 请求数据封装
| +- resp -- Http 响应数据封装
|
+- dao -- 数据访问层,与底层 MySQL 进行数据交互
+- manager -- 通用业务处理层,对第三方平台封装、对 Service 层通用能力的下沉以及对多个 DAO 的组合复用
+- service -- 相对具体的业务逻辑服务层
+- controller -- 主要是处理各种 Http 请求,各类基本参数校验,或者不复用的业务简单处理,返回 JSON 数据等
| +- front -- 小说门户相关接口
| +- author -- 作家管理后台相关接口
| +- admin -- 平台管理后台相关接口
| +- app -- app 接口
| +- applet -- 小程序接口
| +- open -- 开放接口,供第三方调用
# 通用请求/响应数据格式封装
- 在
io.github.xxyopen.novel.core.common.req包下创建分页请求数据格式封装类:
/**
* 分页请求数据格式封装,所有分页请求的 Dto 类都应继承该类
*
* @author xiongxiaoyang
* @date 2022/5/11
*/
@Data
public class PageReqDto {
/**
* 请求页码,默认第 1 页
* */
private int pageNum = 1;
/**
* 每页大小,默认每页 10 条
* */
private int pageSize = 10;
/**
* 是否查询所有,默认不查所有
* 为 true 时,pageNum 和 pageSize 无效
* */
private boolean fetchAll = false;
}
- 在
io.github.xxyopen.novel.core.common.resp包下创建分页响应数据格式封装类:
/**
* 分页响应数据格式封装
*
* @author xiongxiaoyang
* @date 2022/5/11
*/
@Getter
public class PageRespDto<T> {
/**
* 页码
*/
private final long pageNum;
/**
* 每页大小
*/
private final long pageSize;
/**
* 总记录数
*/
private final long total;
/**
* 分页数据集
*/
private final List<? extends T> list;
/**
* 该构造函数用于通用分页查询的场景
* 接收普通分页数据和普通集合
*/
public PageRespDto(long pageNum, long pageSize, long total, List<T> list) {
this.pageNum = pageNum;
this.pageSize = pageSize;
this.total = total;
this.list = list;
}
public static <T> PageRespDto<T> of(long pageNum, long pageSize, long total, List<T> list) {
return new PageRespDto<>(pageNum, pageSize, total, list);
}
/**
* 获取分页数
* */
public long getPages() {
if (this.pageSize == 0L) {
return 0L;
} else {
long pages = this.total / this.pageSize;
if (this.total % this.pageSize != 0L) {
++pages;
}
return pages;
}
}
}
# Rest 接口响应工具及响应数据格式封装
- 在
io.github.xxyopen.novel.core.common.constant包下创建错误码枚举类:
/**
* 错误码枚举类。
*
* 错误码为字符串类型,共 5 位,分成两个部分:错误产生来源+四位数字编号。
* 错误产生来源分为 A/B/C, A 表示错误来源于用户,比如参数错误,用户安装版本过低,用户支付
* 超时等问题; B 表示错误来源于当前系统,往往是业务逻辑出错,或程序健壮性差等问题; C 表示错误来源
* 于第三方服务,比如 CDN 服务出错,消息投递超时等问题;四位数字编号从 0001 到 9999,大类之间的
* 步长间距预留 100。
*
* 错误码分为一级宏观错误码、二级宏观错误码、三级宏观错误码。
* 在无法更加具体确定的错误场景中,可以直接使用一级宏观错误码。
*
* @author xiongxiaoyang
* @date 2022/5/11
*/
@Getter
@AllArgsConstructor
public enum ErrorCodeEnum {
/**
* 正确执行后的返回
* */
OK("00000","一切 ok"),
/**
* 一级宏观错误码,用户端错误
* */
USER_ERROR("A0001","用户端错误"),
/**
* 二级宏观错误码,用户注册错误
* */
USER_REGISTER_ERROR("A0100","用户注册错误"),
/**
* 二级宏观错误码,用户未同意隐私协议
* */
USER_NO_AGREE_PRIVATE_ERROR("A0101","用户未同意隐私协议"),
/**
* 二级宏观错误码,注册国家或地区受限
* */
USER_REGISTER_AREA_LIMIT_ERROR("A0102","注册国家或地区受限"),
/**
* 二级宏观错误码,用户请求参数错误
* */
USER_REQUEST_PARAM_ERROR("A0400","用户请求参数错误"),
// ...省略若干用户端二级宏观错误码
/**
* 一级宏观错误码,系统执行出错
* */
SYSTEM_ERROR("B0001","系统执行出错"),
/**
* 二级宏观错误码,系统执行超时
* */
SYSTEM_TIMEOUT_ERROR("B0100","系统执行超时"),
// ...省略若干系统执行二级宏观错误码
/**
* 一级宏观错误码,调用第三方服务出错
* */
THIRD_SERVICE_ERROR("C0001","调用第三方服务出错"),
/**
* 一级宏观错误码,中间件服务出错
* */
MIDDLEWARE_SERVICE_ERROR("C0100","中间件服务出错")
// ...省略若干三方服务调用二级宏观错误码
;
/**
* 错误码
* */
private String code;
/**
* 中文描述
* */
private String message;
}
- 在
io.github.xxyopen.novel.core.common.resp包下创建 Http Rest 响应工具及数据格式封装类:
/**
* Http Rest 响应工具及数据格式封装
*
* @author xiongxiaoyang
* @date 2022/5/11
*/
@Getter
public class RestResp<T> {
/**
* 响应码
*/
private String code;
/**
* 响应消息
*/
private String message;
/**
* 响应数据
*/
private T data;
private RestResp() {
this.code = ErrorCodeEnum.OK.getCode();
this.message = ErrorCodeEnum.OK.getMessage();
}
private RestResp(ErrorCodeEnum errorCode) {
this.code = errorCode.getCode();
this.message = errorCode.getMessage();
}
private RestResp(T data) {
this.data = data;
}
/**
* 业务处理成功,无数据返回
*/
public static RestResp<Void> ok() {
return new RestResp<>();
}
/**
* 业务处理成功,有数据返回
*/
public static <T> RestResp<T> ok(T data) {
return new RestResp<>(data);
}
/**
* 业务处理失败
*/
public static RestResp<Void> fail(ErrorCodeEnum errorCode) {
return new RestResp<>(errorCode);
}
/**
* 系统错误
*/
public static RestResp<Void> error() {
return new RestResp<>(ErrorCodeEnum.SYSTEM_ERROR);
}
/**
* 判断是否成功
*/
public boolean isOk() {
return Objects.equals(this.code, ErrorCodeEnum.OK.getCode());
}
}
# 通用异常处理
在 Spring 3.2 中,新增了 @ControllerAdvice (opens new window) 注解,用于定义适用于所有 @RequestMapping 方法的 @ExceptionHandler、@InitBinder 和 @ModelAttribute 方法。Spring Boot 默认情况下会映射到 /error 进行异常处理,但是提示十分不友好。我们可以使用该注解定义 @ExceptionHandler 方法来捕获 Controller 抛出的通用异常,并统一进行处理。
- 在
io.github.xxyopen.novel.core.common.exception包下创建自定义业务异常类:
/**
* 自定义业务异常,用于处理用户请求时,业务错误时抛出
*
* @author xiongxiaoyang
* @date 2022/5/11
*/
@EqualsAndHashCode(callSuper = true)
@Data
public class BusinessException extends RuntimeException {
private final ErrorCodeEnum errorCodeEnum;
public BusinessException(ErrorCodeEnum errorCodeEnum) {
// 不调用父类 Throwable的fillInStackTrace() 方法生成栈追踪信息,提高应用性能
// 构造器之间的调用必须在第一行
super(errorCodeEnum.getMessage(), null, false, false);
this.errorCodeEnum = errorCodeEnum;
}
}
- 在
io.github.xxyopen.novel.core.common.exception包下创建通用异常处理器,处理系统异常、数据校验异常和我们自定义的业务异常:
/**
* 通用的异常处理器
*
* @author xiongxiaoyang
* @date 2022/5/11
*/
@Slf4j
@RestControllerAdvice
public class CommonExceptionHandler {
/**
* 处理数据校验异常
* */
@ExceptionHandler(BindException.class)
public RestResp<Void> handlerBindException(BindException e){
log.error(e.getMessage(),e);
return RestResp.fail(ErrorCodeEnum.USER_REQUEST_PARAM_ERROR);
}
/**
* 处理业务异常
* */
@ExceptionHandler(BusinessException.class)
public RestResp<Void> handlerBusinessException(BusinessException e){
log.error(e.getMessage(),e);
return RestResp.fail(e.getErrorCodeEnum());
}
/**
* 处理系统异常
* */
@ExceptionHandler(Exception.class)
public RestResp<Void> handlerException(Exception e){
log.error(e.getMessage(),e);
return RestResp.error();
}
}
# 常量类创建
- 在
io.github.xxyopen.novel.core.common.constant包下创建通用常量类和 API 路由常量类
/**
* 通用常量
*
* @author xiongxiaoyang
* @date 2022/5/12
*/
public class CommonConsts {
/**
* 是
* */
public static final Integer YES = 1;
/**
* 否
* */
public static final Integer NO = 0;
/**
* 性别常量
* */
public enum SexEnum{
/**
* 男
* */
MALE(0,"男"),
/**
* 女
* */
FEMALE(1,"女");
SexEnum(int code,String desc){
this.code = code;
this.desc = desc;
}
private int code;
private String desc;
public int getCode() {
return code;
}
public String getDesc() {
return desc;
}
}
// ...省略若干常量
}
/**
* API 路由常量
*
* @author xiongxiaoyang
* @date 2022/5/12
*/
public class ApiRouterConsts {
/**
* API请求路径前缀
*/
String API_URL_PREFIX = "/api";
/**
* 前台门户系统请求路径前缀
*/
String API_FRONT_URL_PREFIX = API_URL_PREFIX + "/front";
/**
* 作家管理系统请求路径前缀
*/
String API_AUTHOR_URL_PREFIX = API_URL_PREFIX + "/author";
/**
* 平台后台管理系统请求路径前缀
*/
String API_ADMIN_URL_PREFIX = API_URL_PREFIX + "/admin";
/**
* 首页模块请求路径前缀
* */
String HOME_URL_PREFIX = "/home";
/**
* 小说模块请求路径前缀
* */
String BOOK_URL_PREFIX = "/book";
/**
* 会员模块请求路径前缀
* */
String USER_URL_PREFIX = "/user";
/**
* 前台门户首页API请求路径前缀
*/
String API_FRONT_HOME_URL_PREFIX = API_FRONT_URL_PREFIX + HOME_URL_PREFIX;
/**
* 前台门户小说相关API请求路径前缀
*/
String API_FRONT_BOOK_URL_PREFIX = API_FRONT_URL_PREFIX + BOOK_URL_PREFIX;
/**
* 前台门户会员相关API请求路径前缀
*/
String API_FRONT_USER_URL_PREFIX = API_FRONT_URL_PREFIX + USER_URL_PREFIX;
// ...省略若干常量
}
- 在
io.github.xxyopen.novel.core.constant包下创建缓存常量类
/**
* 缓存相关常量
*
* @author xiongxiaoyang
* @date 2022/5/12
*/
public class CacheConsts {
/**
* 本项目 Redis 缓存前缀
* */
public static final String REDIS_CACHE_PREFIX = "Cache::Novel::";
/**
* Caffeine 缓存管理器
* */
public static final String CAFFEINE_CACHE_MANAGER = "caffeineCacheManager";
/**
* Redis 缓存管理器
* */
public static final String REDIS_CACHE_MANAGER = "redisCacheManager";
/**
* 首页小说推荐缓存
* */
public static final String HOME_BOOK_CACHE_NAME = "homeBookCache";
/**
* 首页友情链接缓存
* */
public static final String HOME_FRIEND_LINK_CACHE_NAME = "homeFriendLinkCache";
/**
* 缓存配置常量
*/
public enum CacheEnum {
HOME_BOOK_CACHE(1,HOME_BOOK_CACHE_NAME,0,1),
HOME_FRIEND_LINK_CACHE(2,HOME_FRIEND_LINK_CACHE_NAME,1000,1)
;
/**
* 缓存类型 0-本地 1-本地和远程 2-远程
*/
private int type;
/**
* 缓存的名字
*/
private String name;
/**
* 失效时间(秒) 0-永不失效
*/
private int ttl;
/**
* 最大容量
*/
private int maxSize;
CacheEnum(int type, String name, int ttl, int maxSize) {
this.type = type;
this.name = name;
this.ttl = ttl;
this.maxSize = maxSize;
}
public boolean isLocal() {
return type <= 1;
}
public boolean isRemote() {
return type >= 1;
}
public String getName() {
return name;
}
public int getTtl() {
return ttl;
}
public int getMaxSize() {
return maxSize;
}
}
}
# 日志配置
Spring Boot 默认使用的是 Logback 日志实现,会自动读取类路径下的 logback-spring.xml, logback-spring.groovy, logback.xml, 或 logback.groovy 配置文件。
我们在项目 src/resource 下面添加如下内容的日志配置文件 logback-spring.xml 即可:
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<!-- 彩色日志依赖的渲染类 -->
<conversionRule conversionWord="clr" converterClass="org.springframework.boot.logging.logback.ColorConverter"/>
<conversionRule conversionWord="wex"
converterClass="org.springframework.boot.logging.logback.WhitespaceThrowableProxyConverter"/>
<conversionRule conversionWord="wEx"
converterClass="org.springframework.boot.logging.logback.ExtendedWhitespaceThrowableProxyConverter"/>
<!-- 彩色日志格式 -->
<property name="CONSOLE_LOG_PATTERN"
value="${CONSOLE_LOG_PATTERN:-%clr(%d{yyyy-MM-dd HH:mm:ss.SSS}){faint} %clr(${LOG_LEVEL_PATTERN:-%5p}) %clr(${PID:- }){magenta} %clr(---){faint} %clr([%15.15t]){faint} %clr(%-40.40logger{39}){cyan} %clr(:){faint} %m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}}"/>
<!-- %m输出的信息,%p日志级别,%t线程名,%d日期,%c类的全名,%i索引【从数字0开始递增】,,, -->
<!-- appender是configuration的子节点,是负责写日志的组件。 -->
<!-- ConsoleAppender:把日志输出到控制台 -->
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<!--
<pattern>%d %p (%file:%line\)- %m%n</pattern>
-->
<pattern>${CONSOLE_LOG_PATTERN}</pattern>
<!-- 控制台也要使用UTF-8,不要使用GBK,否则会中文乱码 -->
<charset>UTF-8</charset>
</encoder>
</appender>
<!-- RollingFileAppender:滚动记录文件,先将日志记录到指定文件,当符合某个条件时,将日志记录到其他文件 -->
<!-- 以下的大概意思是:1.先按日期存日志,日期变了,将前一天的日志文件名重命名为XXX%日期%索引,新的日志仍然是demo.log -->
<!-- 2.如果日期没有发生变化,但是当前日志的文件大小超过1KB时,对当前日志进行分割 重命名 -->
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<File>logs/novel.log</File>
<!-- rollingPolicy:当发生滚动时,决定 RollingFileAppender 的行为,涉及文件移动和重命名。 -->
<!-- TimeBasedRollingPolicy: 最常用的滚动策略,它根据时间来制定滚动策略,既负责滚动也负责出发滚动 -->
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!-- 活动文件的名字会根据fileNamePattern的值,每隔一段时间改变一次 -->
<!-- 文件名:logs/demo.2017-12-05.0.log -->
<fileNamePattern>logs/debug.%d.%i.log</fileNamePattern>
<!-- 每产生一个日志文件,该日志文件的保存期限为30天 -->
<maxHistory>30</maxHistory>
<timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
<!-- maxFileSize:这是活动文件的大小,默认值是10MB,测试时可改成1KB看效果 -->
<maxFileSize>10MB</maxFileSize>
</timeBasedFileNamingAndTriggeringPolicy>
</rollingPolicy>
<encoder>
<!-- pattern节点,用来设置日志的输入格式 -->
<pattern>
%d %p (%file:%line\)- %m%n
</pattern>
<!-- 记录日志的编码:此处设置字符集 - -->
<charset>UTF-8</charset>
</encoder>
</appender>
<springProfile name="dev">
<!-- ROOT 日志级别 -->
<root level="INFO">
<appender-ref ref="STDOUT"/>
</root>
<!-- 指定项目中某个包,当有日志操作行为时的日志记录级别 -->
<!-- com.maijinjie.springboot 为根包,也就是只要是发生在这个根包下面的所有日志操作行为的权限都是DEBUG -->
<!-- 级别依次为【从高到低】:FATAL > ERROR > WARN > INFO > DEBUG > TRACE -->
<logger name="io.github.xxyopen" level="DEBUG" additivity="false">
<appender-ref ref="STDOUT"/>
</logger>
</springProfile>
<springProfile name="prod">
<!-- ROOT 日志级别 -->
<root level="INFO">
<appender-ref ref="STDOUT"/>
<appender-ref ref="FILE"/>
</root>
<!-- 指定项目中某个包,当有日志操作行为时的日志记录级别 -->
<!-- com.maijinjie.springboot 为根包,也就是只要是发生在这个根包下面的所有日志操作行为的权限都是DEBUG -->
<!-- 级别依次为【从高到低】:FATAL > ERROR > WARN > INFO > DEBUG > TRACE -->
<logger name="io.github.xxyopen" level="ERROR" additivity="false">
<appender-ref ref="STDOUT"/>
<appender-ref ref="FILE"/>
</logger>
</springProfile>
</configuration>
# 跨域配置
跨域是指浏览器从一个域名的网页去请求另一个域名的资源时,域名、端口、协议任一不同,都是跨域。在前后端分离的模式下,前后端的域名是不一致的,此时就会发生跨域访问问题。
跨域是出于浏览器的同源策略限制,同源策略(Sameoriginpolicy)是一种约定,它是浏览器最核心也最基本的安全功能,如果缺少了同源策略,则浏览器的正常功能可能都会受到影响。
我们可以通过前端配置、后端配置或 nginx 配置来解决跨域问题。
如果选择前端配置,我们可以使用 node 中间件 proxy 配置跨域,前端通过 node proxy 来转发我们的接口请求,和浏览器直接打交道的是 node proxy,这样可以避免浏览器的同源策略。配置示例如下:
proxy: {
'/api': {
target: 'http://localhost:8888',
// 请求改变源,此时 nginx 可以获取到真实的请求 ip
changeOrigin: true
}
}
如果通过 nginx 配置来解决跨域问题,我们在配置 location 路径转发时需要加上如下的配置:
# 允许的请求头
add_header 'Access-Control-Allow-Methods' 'GET,OPTIONS,POST,PUT,DELETE' always;
add_header 'Access-Control-Allow-Credentials' 'true' always;
add_header 'Access-Control-Allow-Origin' '$http_origin' always;
add_header Access-Control-Allow-Headers $http_access_control_request_headers;
add_header Access-Control-Max-Age 3600;
# 头转发
proxy_set_header Host $host;
proxy_set_header X-Real-Ip $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_connect_timeout 1000;
proxy_read_timeout 1000;
# 跨域配置
if ($request_method = OPTIONS ) { return 200; }
因为我们项目的侧重点在后端,而且 Spring MVC 提供了跨域解决方案(CORS (opens new window))的支持。所以我们这里通过后端配置来解决跨域问题。
首先我们需要在 application.yml 配置文件中添加跨域相关的配置:
# 项目配置
novel:
# 跨域配置
cors:
# 允许跨域的域名
allow-origins:
- http://localhost:1024
- http://localhost:8080
然后在io.github.xxyopen.novel.core.config包下创建 CorsProperties 类来绑定 CORS 配置属性:
/**
* 跨域配置属性
*
* @author xiongxiaoyang
* @date 2022/5/17
*/
@ConfigurationProperties(prefix = "novel.cors")
@Data
public class CorsProperties {
/**
* 允许跨域的域名
* */
private List<String> allowOrigins;
}
最后在io.github.xxyopen.novel.core.config包下增加如下的 CORS 配置类:
/**
* 跨域配置
*
* @author xiongxiaoyang
* @date 2022/5/13
*/
@Configuration
@EnableConfigurationProperties(CorsProperties.class)
@RequiredArgsConstructor
public class CorsConfig {
private final CorsProperties corsProperties;
@Bean
public CorsFilter corsFilter() {
CorsConfiguration config = new CorsConfiguration();
// 允许的域,不要写*,否则cookie就无法使用了
for (String allowOrigin : corsProperties.getAllowOrigins()) {
config.addAllowedOrigin(allowOrigin);
}
// 允许的头信息
config.addAllowedHeader("*");
// 允许的请求方式
config.addAllowedMethod("*");
// 是否允许携带Cookie信息
config.setAllowCredentials(true);
UrlBasedCorsConfigurationSource configurationSource = new UrlBasedCorsConfigurationSource();
// 添加映射路径,拦截一切请求
configurationSource.registerCorsConfiguration("/**",config);
return new CorsFilter(configurationSource);
}
}
# Mybatis 增强工具 MyBatis-Plus 集成
[MyBatis-Plus] (https://baomidou.com)是一个 MyBatis (https://www.mybatis.org/mybatis-3)的增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发、提高效率而生。我们可以按照如下步骤集成到我们的项目中:
- 添加 mybatis-plus 的启动器依赖
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.1</version>
</dependency>
- 配置 MapperScan 注解
@SpringBootApplication
@MapperScan("io.github.xxyopen.novel.dao.mapper")
public class NovelApplication {
public static void main(String[] args) {
SpringApplication.run(NovelApplication.class, args);
}
}
- 因为我们系统涉及分页数据查询,所以我们还需要在
io.github.xxyopen.novel.core.config包下配置 mybatis-plus 的分页插件:
/**
* Mybatis-Plus 配置类
*
* @author xiongxiaoyang
* @date 2022/5/16
*/
@Configuration
public class MybatisPlusConfig {
/**
* 分页插件
*/
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
return interceptor;
}
}
- 数据源配置
YAML 是 JSON 的超集,一种用于指定分层配置数据的便捷格式。本项目中我们统一使用 YAML 格式的配置文件,所以先将 resources 目录下的 application.properties 文件重命名为 application.yml,
然后在 application.yml 配置文件中加入以下数据源配置:
spring:
datasource:
url: jdbc:mysql://localhost:3306/novel?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai
username: root
password: test123456
注:根据实际的数据库环境来修改相应的IP、端口号、数据库名、用户名和密码
- 为了兼容 Spring Boot 3(Spring 6),在
org.springframework.core包下创建NestedIOException异常类
/**
* 兼容 mybatis-plus 3.5.1
* mybatis-plus 的 MybatisSqlSessionFactoryBean 中使用到了这个异常
* Spring 6 开始移除了该异常
*
* @author xiongxiaoyang
* @date 2022/5/12
*/
public class NestedIOException extends IOException {
}
# 代码生成器 Mybatis-Plus-Generator 集成
- 添加相关依赖
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-generator</artifactId>
<version>${mybatis-plus.version}</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.velocity</groupId>
<artifactId>velocity-engine-core</artifactId>
<version>2.3</version>
<scope>test</scope>
</dependency>
- 在 test/resources/templates 下面创建以下模版文件
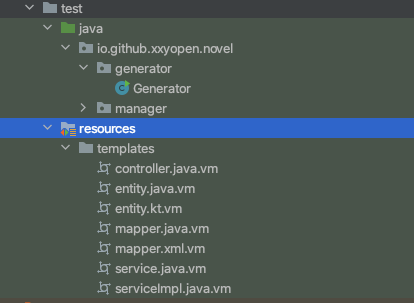
- 在 test/java 下面创建代码生成器类
/**
* 代码生成器
*
* @author xiongxiaoyang
* @date 2022/5/11
*/
public class Generator {
private static final String USERNAME = System.getenv().get("USER");
/**
* 项目信息
*/
private static final String PROJECT_PATH = System.getProperty("user.dir");
private static final String JAVA_PATH = "/src/main/java";
private static final String RESOURCE_PATH = "/src/main/resources";
private static final String BASE_PACKAGE = "io.github.xxyopen.novel";
/**
* 数据库信息
*/
private static final String DATABASE_IP = "127.0.0.1";
private static final String DATABASE_PORT = "3306";
private static final String DATABASE_NAME = "novel";
private static final String DATABASE_USERNAME = "root";
private static final String DATABASE_PASSWORD = "test123456";
public static void main(String[] args) {
// 传入需要生成的表名,多个用英文逗号分隔,所有用 all 表示
genCode("sys_user");
}
/**
* 代码生成
*/
private static void genCode(String tables) {
// 全局配置
FastAutoGenerator.create(String.format("jdbc:mysql://%s:%s/%s?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai", DATABASE_IP, DATABASE_PORT, DATABASE_NAME), DATABASE_USERNAME, DATABASE_PASSWORD)
.globalConfig(builder -> {
builder.author(USERNAME) // 设置作者
.fileOverride()
// kotlin
//.enableSwagger() // 开启 swagger 模式
.fileOverride() // 覆盖已生成文件
.commentDate("yyyy/MM/dd")
.outputDir(PROJECT_PATH + JAVA_PATH); // 指定输出目录
})
// 包配置
.packageConfig(builder -> builder.parent(BASE_PACKAGE) // 设置父包名
.entity("dao.entity")
.service("service")
.serviceImpl("service.impl")
.mapper("dao.mapper")
.controller("controller.front")
.pathInfo(Collections.singletonMap(OutputFile.mapperXml, PROJECT_PATH + RESOURCE_PATH + "/mapper")))
// 模版配置
.templateConfig(builder -> builder.disable(TemplateType.SERVICE)
.disable(TemplateType.SERVICEIMPL)
.disable(TemplateType.CONTROLLER))
// 策略配置
.strategyConfig(builder -> builder.addInclude(getTables(tables)) // 设置需要生成的表名
.controllerBuilder()
.enableRestStyle()
.serviceBuilder()
.formatServiceFileName("%sService")
) // 开启生成@RestController 控制器
//.templateEngine(new FreemarkerTemplateEngine()) // 使用Freemarker引擎模板,默认的是Velocity引擎模板
.execute();
}
/**
* 处理 all 和多表情况
*/
protected static List<String> getTables(String tables) {
return "all".equals(tables) ? Collections.emptyList() : Arrays.asList(tables.split(","));
}
}
- 修改 Generator 类中数据库相关配置,选择我们需要创建的表名(all),运行 main 方法生成代码
# 本地缓存 Caffeine 集成和配置
Caffeine 是 Java 8 对 Google Guava 缓存的重写,是一个提供了近乎最佳命中率的高性能的缓存库。我们按照如下步骤集成和配置:
- 添加 spring-boot-starter-cache 依赖
使用 spring-boot-starter-cache “Starter” 可以快速添加基本缓存依赖项。 starter 引入了 spring-context-support。如果我们手动添加依赖项,则必须包含 spring-context-support 才能使用 JCache 或 Caffeine 支持。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
- 添加 caffeine 依赖
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
</dependency>
- 自定义缓存管理器
/**
* Caffeine 缓存管理器
*/
@Bean
public CacheManager caffeineCacheManager() {
SimpleCacheManager cacheManager = new SimpleCacheManager();
List<CaffeineCache> caches = new ArrayList<>(CacheConsts.CacheEnum.values().length);
for (CacheConsts.CacheEnum c : CacheConsts.CacheEnum.values()) {
if (c.isLocal()) {
Caffeine<Object, Object> caffeine = Caffeine.newBuilder().recordStats().maximumSize(c.getMaxSize());
if (c.getTtl() > 0) {
caffeine.expireAfterWrite(Duration.ofSeconds(c.getTtl()));
}
caches.add(new CaffeineCache(c.getName(), caffeine.build()));
}
}
cacheManager.setCaches(caches);
return cacheManager;
}
- 使用 @EnableCaching 注解开启缓存
@SpringBootApplication
@MapperScan("io.github.xxyopen.novel.dao.mapper")
@EnableCaching
@Slf4j
public class NovelApplication {
public static void main(String[] args) {
SpringApplication.run(NovelApplication.class, args);
}
@Bean
public CommandLineRunner commandLineRunner(ApplicationContext context){
return args -> {
Map<String, CacheManager> beans = context.getBeansOfType(CacheManager.class);
log.info("加载了如下缓存管理器:");
beans.forEach((k,v)->{
log.info("{}:{}",k,v.getClass().getName());
log.info("缓存:{}",v.getCacheNames());
});
};
}
}
这样我们就可以使用 Spring Cache 的注解(例如 @Cacheable)开发了。
# 分布式缓存 Redis 集成和配置
本地缓存虽然有着访问速度快的优点,但无法进行大数据的存储。并且当我们集群部署多个服务节点,或者后期随着业务发展进行服务拆分后,没法共享缓存和保证缓存数据的一致性。 本地缓存的数据还会随应用程序的重启而丢失,这样对于需要持久化的数据满足不了需求,还会导致重启后数据库瞬时压力过大。
所以本地缓存一般适合于缓存只读数据,如统计类数据,或者每个部署节点独立的数据。其它情况就需要用到分布式缓存了。
分布式缓存的集成步骤和本地缓存基本差不多,除了替换 caffeine 的依赖项为我们 redis 的依赖和配置上我们自定义的 redis 缓存管理器外,还要在配置文件中加入 redis 的连接配置:
- 加入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
- 配置 redis 缓存管理器
/**
* 缓存配置类
*
* @author xiongxiaoyang
* @date 2022/5/12
*/
@Configuration
public class CacheConfig {
/**
* Caffeine 缓存管理器
*/
@Bean
@Primary
public CacheManager caffeineCacheManager() {
SimpleCacheManager cacheManager = new SimpleCacheManager();
List<CaffeineCache> caches = new ArrayList<>(CacheConsts.CacheEnum.values().length);
for (CacheConsts.CacheEnum c : CacheConsts.CacheEnum.values()) {
if (c.isLocal()) {
Caffeine<Object, Object> caffeine = Caffeine.newBuilder().recordStats().maximumSize(c.getMaxSize());
if (c.getTtl() > 0) {
caffeine.expireAfterWrite(Duration.ofSeconds(c.getTtl()));
}
caches.add(new CaffeineCache(c.getName(), caffeine.build()));
}
}
cacheManager.setCaches(caches);
return cacheManager;
}
/**
* Redis 缓存管理器
*/
@Bean
public CacheManager redisCacheManager(RedisConnectionFactory connectionFactory) {
RedisCacheWriter redisCacheWriter = RedisCacheWriter.nonLockingRedisCacheWriter(connectionFactory);
RedisCacheConfiguration defaultCacheConfig = RedisCacheConfiguration.defaultCacheConfig()
.disableCachingNullValues().prefixCacheNameWith(CacheConsts.REDIS_CACHE_PREFIX);
Map<String, RedisCacheConfiguration> cacheMap = new LinkedHashMap<>(CacheConsts.CacheEnum.values().length);
for (CacheConsts.CacheEnum c : CacheConsts.CacheEnum.values()) {
if (c.isRemote()) {
if (c.getTtl() > 0) {
cacheMap.put(c.getName(), RedisCacheConfiguration.defaultCacheConfig().disableCachingNullValues()
.prefixCacheNameWith(CacheConsts.REDIS_CACHE_PREFIX).entryTtl(Duration.ofSeconds(c.getTtl())));
} else {
cacheMap.put(c.getName(), RedisCacheConfiguration.defaultCacheConfig().disableCachingNullValues()
.prefixCacheNameWith(CacheConsts.REDIS_CACHE_PREFIX));
}
}
}
RedisCacheManager redisCacheManager = new RedisCacheManager(redisCacheWriter, defaultCacheConfig, cacheMap);
redisCacheManager.setTransactionAware(true);
redisCacheManager.initializeCaches();
return redisCacheManager;
}
}
- application.yml 中加入 redis 连接配置信息
spring:
redis:
host: 127.0.0.1
port: 6379
password: 123456
# 搜索引擎 Elasticsearch 集成与配置
# 介绍
Elastic Stack 是一个可以帮助我们构建搜索体验、解决问题并取得成功的搜索平台。核心产品包括 Elasticsearch、Kibana、Beats 和 Logstash(也称为 ELK Stack (opens new window))等等。能够安全可靠地获取任何来源、任何格式的数据,然后实时地对数据进行搜索、分析和可视化。
Elasticsearch 和 Kibana 都是在免费开源的基础上构建而成,适用于各种各样的用例,从日志开始,到能够想到的任何项目,无一不能胜任。
Elasticsearch 是一个基于 JSON 的分布式、RESTful 风格的搜索和数据分析引擎,能够解决不断涌现出的各种用例。 作为 Elastic Stack 的核心,它集中存储数据,帮助发现意料之中以及意料之外的情况。
Kibana 是一个免费且开放的用户界面,能够对 Elasticsearch 数据进行可视化,并在 Elastic Stack 中进行导航。我们可以进行各种操作,从跟踪查询负载,到理解请求如何流经整个应用,都能轻松完成。
# 集成与配置
Elasticsearch 和 Kibana 安装,如果不想在本地安装 Elasticsearch 和 Kibana,可以使用官方提供的免费试用版 Elastic Cloud (opens new window)
Kibana 中创建索引:
PUT /book
{
"mappings" : {
"properties" : {
"id" : {
"type" : "long"
},
"authorId" : {
"type" : "long"
},
"authorName" : {
"type" : "text",
"analyzer": "ik_smart"
},
"bookName" : {
"type" : "text",
"analyzer": "ik_smart"
},
"bookDesc" : {
"type" : "text",
"analyzer": "ik_smart"
},
"bookStatus" : {
"type" : "short"
},
"categoryId" : {
"type" : "integer"
},
"categoryName" : {
"type" : "text",
"analyzer": "ik_smart"
},
"lastChapterId" : {
"type" : "long"
},
"lastChapterName" : {
"type" : "text",
"analyzer": "ik_smart"
},
"lastChapterUpdateTime" : {
"type": "long"
},
"picUrl" : {
"type" : "keyword",
"index" : false,
"doc_values" : false
},
"score" : {
"type" : "integer"
},
"wordCount" : {
"type" : "integer"
},
"workDirection" : {
"type" : "short"
},
"visitCount" : {
"type": "long"
}
}
}
}
- 项目添加如下依赖:
<dependencies>
<dependency>
<groupId>co.elastic.clients</groupId>
<artifactId>elasticsearch-java</artifactId>
<version>8.2.0</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.12.3</version>
</dependency>
</dependencies>
- 在 application.yml 中配置如下连接信息:
spring:
elasticsearch:
uris:
- https://my-deployment-ce7ca3.es.us-central1.gcp.cloud.es.io:9243
username: elastic
password: qTjgYVKSuExX
/**
* elasticsearch 相关配置
*
* @author xiongxiaoyang
* @date 2022/5/23
*/
@Configuration
@ConditionalOnProperty(prefix = "spring.elasticsearch", name = "enable", havingValue = "true")
@RequiredArgsConstructor
public class EsConfig {
@Bean
public ElasticsearchClient elasticsearchClient(RestClient restClient) {
// Create the transport with a Jackson mapper
ElasticsearchTransport transport = new RestClientTransport(
restClient, new JacksonJsonpMapper());
// And create the API client
return new ElasticsearchClient(transport);
}
}
# Spring AMQP 集成与配置
# 介绍
AMQP(高级消息队列协议)是一个异步消息传递所使用的应用层协议规范,为面向消息的中间件设计,不受产品和开发语言的限制. Spring AMQP 将核心 Spring 概念应用于基于 AMQP 消息传递解决方案的开发。
RabbitMQ 是基于 AMQP 协议的轻量级、可靠、可扩展、可移植的消息中间件,Spring 使用 RabbitMQ 通过 AMQP 协议进行通信。Spring Boot 为通过 RabbitMQ 使用 AMQP 提供了多种便利,包括 spring-boot-starter-amqp “Starter”。
# 集成与配置
- 可通过如下 Docker 命令 安装 RabbiMQ:
docker run -it --rm --name rabbitmq -p 5672:5672 -p 15672:15672 rabbitmq:3.10-management
- 登录 RabbiMQ 的 web 管理界面,创建虚拟主机
novel:
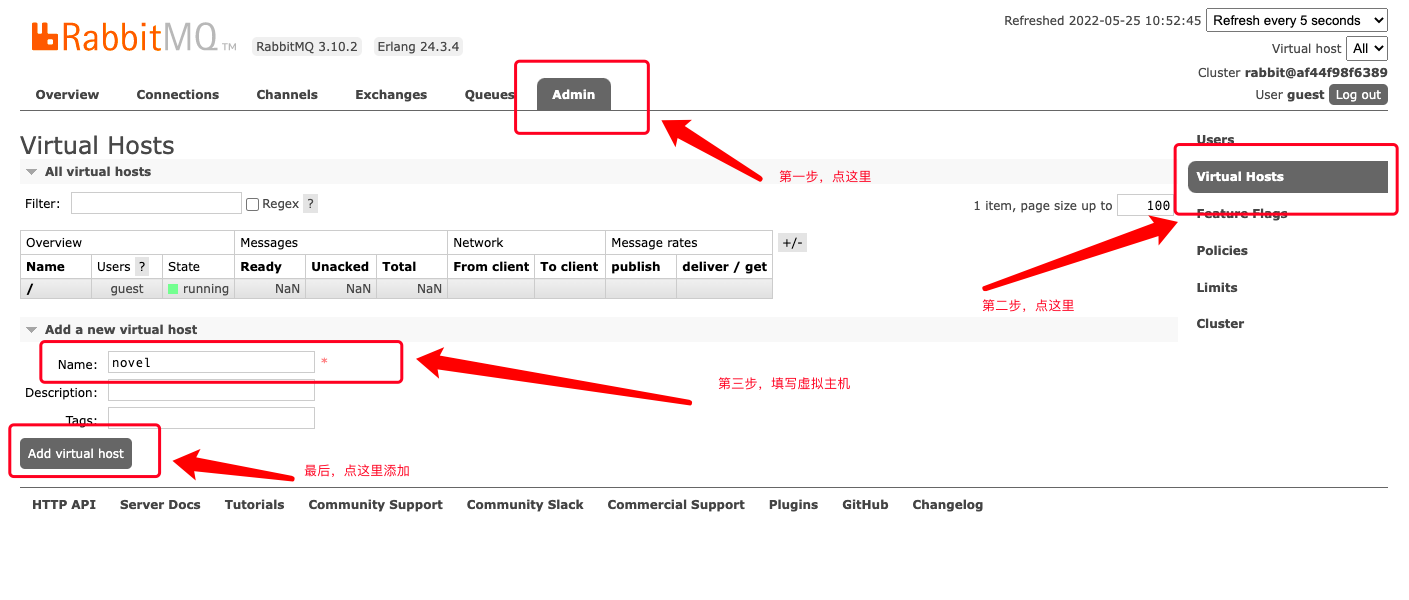
- 项目中加入如下的 maven 依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
- 在 application.yml 配置文件中加入 RabbitMQ 的连接配置:
spring:
rabbitmq:
addresses: "amqp://guest:guest@47.106.243.172"
virtual-host: novel
template:
retry:
# 开启重试
enabled: true
# 最大重试次数
max-attempts: 3
# 第一次和第二次重试之间的持续时间
initial-interval: "3s"
- 在 Spring Beans 中注入 AmqpTemplate 发送消息
# 分布式任务调度平台 XXL-JOB 集成与配置
# 介绍
XXL-JOB 是一个开箱即用的开源分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。由调度模块和执行模块构成:
- 调度模块(调度中心):
负责管理调度信息,按照调度配置发出调度请求,自身不承担业务代码。调度系统与任务解耦,提高了系统可用性和稳定性,同时调度系统性能不再受限于任务模块; 支持可视化、简单且动态的管理调度信息,包括任务新建,更新,删除,GLUE开发和任务报警等,所有上述操作都会实时生效,同时支持监控调度结果以及执行日志,支持执行器Failover。
- 执行模块(执行器):
负责接收调度请求并执行任务逻辑。任务模块专注于任务的执行等操作,开发和维护更加简单和高效; 接收“调度中心”的执行请求、终止请求和日志请求等。
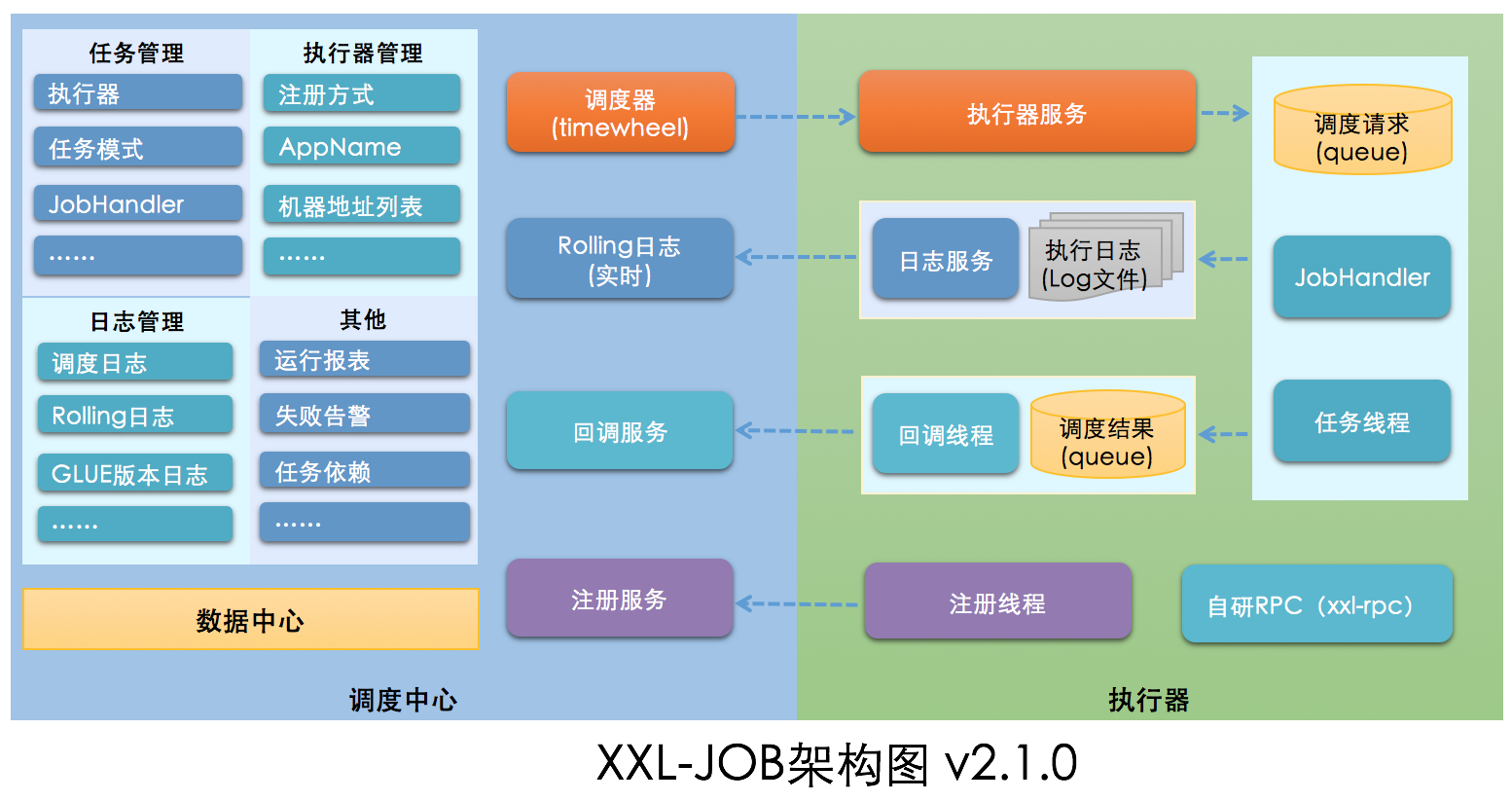
XXL-JOB 将调度行为抽象形成“调度中心”公共平台,而平台自身并不承担业务逻辑,“调度中心”负责发起调度请求。
将任务抽象成分散的JobHandler,交由“执行器”统一管理,“执行器”负责接收调度请求并执行对应的JobHandler中业务逻辑。
因此,“调度”和“任务”两部分可以相互解耦,提高系统整体稳定性和扩展性;
XXL-JOB 的主要功能特性如下:
- 简单:支持通过 Web 页面对任务进行 CRUD 操作,操作简单,一分钟上手;
- 动态:支持动态修改任务状态、启动/停止任务,以及终止运行中任务,即时生效;
- 调度中心 HA(中心式):调度采用中心式设计,“调度中心”自研调度组件并支持集群部署,可保证调度中心 HA;
- 执行器 HA(分布式):任务分布式执行,任务”执行器”支持集群部署,可保证任务执行 HA;
- 注册中心: 执行器会周期性自动注册任务, 调度中心将会自动发现注册的任务并触发执行。同时,也支持手动录入执行器地址;
- 弹性扩容缩容:一旦有新执行器机器上线或者下线,下次调度时将会重新分配任务;
- 触发策略:提供丰富的任务触发策略,包括:Cron 触发、固定间隔触发、固定延时触发、API(事件)触发、人工触发、父子任务触发;
- 调度过期策略:调度中心错过调度时间的补偿处理策略,包括:忽略、立即补偿触发一次等;
- 阻塞处理策略:调度过于密集执行器来不及处理时的处理策略,策略包括:单机串行(默认)、丢弃后续调度、覆盖之前调度;
- 任务超时控制:支持自定义任务超时时间,任务运行超时将会主动中断任务;
- 任务失败重试:支持自定义任务失败重试次数,当任务失败时将会按照预设的失败重试次数主动进行重试;其中分片任务支持分片粒度的失败重试;
- 任务失败告警;默认提供邮件方式失败告警,同时预留扩展接口,可方便的扩展短信、钉钉等告警方式;
- 路由策略:执行器集群部署时提供丰富的路由策略,包括:第一个、最后一个、轮询、随机、一致性 HASH、最不经常使用、最近最久未使用、故障转移、忙碌转移等;
- 分片广播任务:执行器集群部署时,任务路由策略选择”分片广播”情况下,一次任务调度将会广播触发集群中所有执行器执行一次任务,可根据分片参数开发分片任务;
- 动态分片:分片广播任务以执行器为维度进行分片,支持动态扩容执行器集群从而动态增加分片数量,协同进行业务处理;在进行大数据量业务操作时可显著提升任务处理能力和速度。
- 故障转移:任务路由策略选择”故障转移”情况下,如果执行器集群中某一台机器故障,将会自动Failover切换到一台正常的执行器发送调度请求。
- 任务进度监控:支持实时监控任务进度;
- Rolling 实时日志:支持在线查看调度结果,并且支持以 Rolling 方式实时查看执行器输出的完整的执行日志;
- GLUE:提供Web IDE,支持在线开发任务逻辑代码,动态发布,实时编译生效,省略部署上线的过程。支持30个版本的历史版本回溯。
- 脚本任务:支持以GLUE模式开发和运行脚本任务,包括 Shell、Python、NodeJS、PHP、PowerShell等类型脚本;
- 命令行任务:原生提供通用命令行任务Handler(Bean任务,”CommandJobHandler”);业务方只需要提供命令行即可;
- 任务依赖:支持配置子任务依赖,当父任务执行结束且执行成功后将会主动触发一次子任务的执行, 多个子任务用逗号分隔;
- 一致性:“调度中心”通过DB锁保证集群分布式调度的一致性, 一次任务调度只会触发一次执行;
- 自定义任务参数:支持在线配置调度任务入参,即时生效;
- 调度线程池:调度系统多线程触发调度运行,确保调度精确执行,不被堵塞;
- 数据加密:调度中心和执行器之间的通讯进行数据加密,提升调度信息安全性;
- 邮件报警:任务失败时支持邮件报警,支持配置多邮件地址群发报警邮件;
- 推送 maven 中央仓库: 将会把最新稳定版推送到 maven 中央仓库, 方便用户接入和使用;
- 运行报表:支持实时查看运行数据,如任务数量、调度次数、执行器数量等;以及调度报表,如调度日期分布图,调度成功分布图等;
- 全异步:任务调度流程全异步化设计实现,如异步调度、异步运行、异步回调等,有效对密集调度进行流量削峰,理论上支持任意时长任务的运行;
- 跨语言:调度中心与执行器提供语言无关的 RESTful API 服务,第三方任意语言可据此对接调度中心或者实现执行器。除此之外,还提供了 “多任务模式”和“httpJobHandler”等其他跨语言方案;
- 国际化:调度中心支持国际化设置,提供中文、英文两种可选语言,默认为中文;
- 容器化:提供官方 docker 镜像,并实时更新推送 dockerhub,进一步实现产品开箱即用;
- 线程池隔离:调度线程池进行隔离拆分,慢任务自动降级进入”Slow”线程池,避免耗尽调度线程,提高系统稳定性;
- 用户管理:支持在线管理系统用户,存在管理员、普通用户两种角色;
- 权限控制:执行器维度进行权限控制,管理员拥有全量权限,普通用户需要分配执行器权限后才允许相关操作;
# 集成与配置
- 初始化如下的
调度数据库:
#
# XXL-JOB v2.4.0-SNAPSHOT
# Copyright (c) 2015-present, xuxueli.
CREATE database if NOT EXISTS `xxl_job` default character set utf8mb4 collate utf8mb4_unicode_ci;
use `xxl_job`;
SET NAMES utf8mb4;
CREATE TABLE `xxl_job_info` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`job_group` int(11) NOT NULL COMMENT '执行器主键ID',
`job_desc` varchar(255) NOT NULL,
`add_time` datetime DEFAULT NULL,
`update_time` datetime DEFAULT NULL,
`author` varchar(64) DEFAULT NULL COMMENT '作者',
`alarm_email` varchar(255) DEFAULT NULL COMMENT '报警邮件',
`schedule_type` varchar(50) NOT NULL DEFAULT 'NONE' COMMENT '调度类型',
`schedule_conf` varchar(128) DEFAULT NULL COMMENT '调度配置,值含义取决于调度类型',
`misfire_strategy` varchar(50) NOT NULL DEFAULT 'DO_NOTHING' COMMENT '调度过期策略',
`executor_route_strategy` varchar(50) DEFAULT NULL COMMENT '执行器路由策略',
`executor_handler` varchar(255) DEFAULT NULL COMMENT '执行器任务handler',
`executor_param` varchar(512) DEFAULT NULL COMMENT '执行器任务参数',
`executor_block_strategy` varchar(50) DEFAULT NULL COMMENT '阻塞处理策略',
`executor_timeout` int(11) NOT NULL DEFAULT '0' COMMENT '任务执行超时时间,单位秒',
`executor_fail_retry_count` int(11) NOT NULL DEFAULT '0' COMMENT '失败重试次数',
`glue_type` varchar(50) NOT NULL COMMENT 'GLUE类型',
`glue_source` mediumtext COMMENT 'GLUE源代码',
`glue_remark` varchar(128) DEFAULT NULL COMMENT 'GLUE备注',
`glue_updatetime` datetime DEFAULT NULL COMMENT 'GLUE更新时间',
`child_jobid` varchar(255) DEFAULT NULL COMMENT '子任务ID,多个逗号分隔',
`trigger_status` tinyint(4) NOT NULL DEFAULT '0' COMMENT '调度状态:0-停止,1-运行',
`trigger_last_time` bigint(13) NOT NULL DEFAULT '0' COMMENT '上次调度时间',
`trigger_next_time` bigint(13) NOT NULL DEFAULT '0' COMMENT '下次调度时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`job_group` int(11) NOT NULL COMMENT '执行器主键ID',
`job_id` int(11) NOT NULL COMMENT '任务,主键ID',
`executor_address` varchar(255) DEFAULT NULL COMMENT '执行器地址,本次执行的地址',
`executor_handler` varchar(255) DEFAULT NULL COMMENT '执行器任务handler',
`executor_param` varchar(512) DEFAULT NULL COMMENT '执行器任务参数',
`executor_sharding_param` varchar(20) DEFAULT NULL COMMENT '执行器任务分片参数,格式如 1/2',
`executor_fail_retry_count` int(11) NOT NULL DEFAULT '0' COMMENT '失败重试次数',
`trigger_time` datetime DEFAULT NULL COMMENT '调度-时间',
`trigger_code` int(11) NOT NULL COMMENT '调度-结果',
`trigger_msg` text COMMENT '调度-日志',
`handle_time` datetime DEFAULT NULL COMMENT '执行-时间',
`handle_code` int(11) NOT NULL COMMENT '执行-状态',
`handle_msg` text COMMENT '执行-日志',
`alarm_status` tinyint(4) NOT NULL DEFAULT '0' COMMENT '告警状态:0-默认、1-无需告警、2-告警成功、3-告警失败',
PRIMARY KEY (`id`),
KEY `I_trigger_time` (`trigger_time`),
KEY `I_handle_code` (`handle_code`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_log_report` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`trigger_day` datetime DEFAULT NULL COMMENT '调度-时间',
`running_count` int(11) NOT NULL DEFAULT '0' COMMENT '运行中-日志数量',
`suc_count` int(11) NOT NULL DEFAULT '0' COMMENT '执行成功-日志数量',
`fail_count` int(11) NOT NULL DEFAULT '0' COMMENT '执行失败-日志数量',
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `i_trigger_day` (`trigger_day`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_logglue` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`job_id` int(11) NOT NULL COMMENT '任务,主键ID',
`glue_type` varchar(50) DEFAULT NULL COMMENT 'GLUE类型',
`glue_source` mediumtext COMMENT 'GLUE源代码',
`glue_remark` varchar(128) NOT NULL COMMENT 'GLUE备注',
`add_time` datetime DEFAULT NULL,
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_registry` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`registry_group` varchar(50) NOT NULL,
`registry_key` varchar(255) NOT NULL,
`registry_value` varchar(255) NOT NULL,
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `i_g_k_v` (`registry_group`,`registry_key`,`registry_value`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_group` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`app_name` varchar(64) NOT NULL COMMENT '执行器AppName',
`title` varchar(12) NOT NULL COMMENT '执行器名称',
`address_type` tinyint(4) NOT NULL DEFAULT '0' COMMENT '执行器地址类型:0=自动注册、1=手动录入',
`address_list` text COMMENT '执行器地址列表,多地址逗号分隔',
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`username` varchar(50) NOT NULL COMMENT '账号',
`password` varchar(50) NOT NULL COMMENT '密码',
`role` tinyint(4) NOT NULL COMMENT '角色:0-普通用户、1-管理员',
`permission` varchar(255) DEFAULT NULL COMMENT '权限:执行器ID列表,多个逗号分割',
PRIMARY KEY (`id`),
UNIQUE KEY `i_username` (`username`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE `xxl_job_lock` (
`lock_name` varchar(50) NOT NULL COMMENT '锁名称',
PRIMARY KEY (`lock_name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
INSERT INTO `xxl_job_group`(`id`, `app_name`, `title`, `address_type`, `address_list`, `update_time`) VALUES (1, 'xxl-job-executor-sample', '示例执行器', 0, NULL, '2018-11-03 22:21:31' );
INSERT INTO `xxl_job_info`(`id`, `job_group`, `job_desc`, `add_time`, `update_time`, `author`, `alarm_email`, `schedule_type`, `schedule_conf`, `misfire_strategy`, `executor_route_strategy`, `executor_handler`, `executor_param`, `executor_block_strategy`, `executor_timeout`, `executor_fail_retry_count`, `glue_type`, `glue_source`, `glue_remark`, `glue_updatetime`, `child_jobid`) VALUES (1, 1, '测试任务1', '2018-11-03 22:21:31', '2018-11-03 22:21:31', 'XXL', '', 'CRON', '0 0 0 * * ? *', 'DO_NOTHING', 'FIRST', 'demoJobHandler', '', 'SERIAL_EXECUTION', 0, 0, 'BEAN', '', 'GLUE代码初始化', '2018-11-03 22:21:31', '');
INSERT INTO `xxl_job_user`(`id`, `username`, `password`, `role`, `permission`) VALUES (1, 'admin', 'e10adc3949ba59abbe56e057f20f883e', 1, NULL);
INSERT INTO `xxl_job_lock` ( `lock_name`) VALUES ( 'schedule_lock');
commit;
注:调度中心支持集群部署,集群情况下各节点务必连接同一个 mysql 实例,如果 mysql 做主从,调度中心集群节点务必强制走主库。
- Docker 镜像方式搭建调度中心:
/**
* 如需自定义 mysql 等配置,可通过 "-e PARAMS" 指定,参数格式 PARAMS="--key=value --key2=value2" ;
* 如需自定义 JVM 内存参数 等配置,可通过 "-e JAVA_OPTS" 指定,参数格式 JAVA_OPTS="-Xmx512m" ;
*/
docker run \
-e PARAMS=' \
--spring.datasource.url=jdbc:mysql://47.106.243.172:3306/xxl_job?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai \
--spring.datasource.username=test \
--spring.datasource.password=test!1234 \
--xxl.job.accessToken=123' \
-p 8080:8080 \
-v /tmp:/data/applogs \
--name xxl-job-admin \
-d xuxueli/xxl-job-admin:{指定版本}
注:如上所示,数据库密码中如果包含特殊字符(例如,& 或 !),需要对特殊字符进行转义,PARAMS 参数值一定要使用使用单引号而不能使用双引号。
| 常用转义字符 | 作用 |
|---|---|
| 反斜杠(\) | 使反斜杠后面的一个变量变为单纯的字符串,如果放在引号里面,是不起作用的 |
| 单引号(’’) | 转义其中所有的变量为单纯的字符串 |
| 双引号("") | 保留其中的变量属性,不进行转义处理 |
调度中心访问地址:http://ip:8080/xxl-job-admin (该地址执行器将会使用到,作为回调地址)
默认登录账号 “admin/123456”,登录后如下图所示:
- 项目中引入
xxl-job-core的 maven 依赖:
<dependency>
<groupId>com.xuxueli</groupId>
<artifactId>xxl-job-core</artifactId>
<version>2.3.1</version>
</dependency>
- application.yml 中加入执行器配置:
# XXL-JOB 配置
xxl:
job:
admin:
### 调度中心部署根地址 [选填]:如调度中心集群部署存在多个地址则用逗号分隔。执行器将会使用该地址进行"执行器心跳注册"和"任务结果回调";为空则关闭自动注册;
addresses: http://127.0.0.1:8080/xxl-job-admin
executor:
### 执行器AppName [选填]:执行器心跳注册分组依据;为空则关闭自动注册
appname: xxl-job-executor-novel
### 执行器运行日志文件存储磁盘路径 [选填] :需要对该路径拥有读写权限;为空则使用默认路径;
logpath: logs/xxl-job/jobhandler
### xxl-job, access token
accessToken: 123
- 在
io.github.xxyopen.novel.core.config包下创建 XXL-JOB 配置类配置执行器组件:
/**
* XXL-JOB 配置类
*
* @author xiongxiaoyang
* @date 2022/5/31
*/
@Configuration
@Slf4j
public class XxlJobConfig {
@Value("${xxl.job.admin.addresses}")
private String adminAddresses;
@Value("${xxl.job.accessToken}")
private String accessToken;
@Value("${xxl.job.executor.appname}")
private String appname;
@Value("${xxl.job.executor.logpath}")
private String logPath;
@Bean
public XxlJobSpringExecutor xxlJobExecutor() {
log.info(">>>>>>>>>>> xxl-job config init.");
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
xxlJobSpringExecutor.setAdminAddresses(adminAddresses);
xxlJobSpringExecutor.setAccessToken(accessToken);
xxlJobSpringExecutor.setAppname(appname);
xxlJobSpringExecutor.setLogPath(logPath);
return xxlJobSpringExecutor;
}
}
# 接口开发
# 接口规约
协议:生产环境必须使用 HTTPS。
路径:每一个 API 需对应一个路径,表示 API 具体的请求地址:
a) 代表一种资源,只能为名词,推荐使用复数,不能为动词,请求方法已经表达动作意义。
b) URL 路径不能使用大写,单词如果需要分隔,统一使用下划线。
c) 路径禁止携带表示请求内容类型的后缀,比如".json",".xml",通过 accept 头表达即可。
请求方法:对具体操作的定义,常见的请求方法如下:
a) GET:从服务器取出资源。
b) POST:在服务器新建一个资源。
c) PUT:在服务器更新资源。
d) DELETE:从服务器删除资源。
请求内容: URL 带的参数必须无敏感信息或符合安全要求; body 里带参数时必须设置 Content-Type。
响应体:响应体 body 可放置多种数据类型,由 Content-Type 头来确定。
# Service/DAO 层方法命名规约
获取单个对象的方法用 get 做前缀。
获取多个对象的方法用 list 做前缀,复数结尾,如: listObjects。
获取统计值的方法用 count 做前缀。
插入的方法用 save/insert 做前缀。
删除的方法用 remove/delete 做前缀。
修改的方法用 update 做前缀。
# 首页相关接口开发
首页 UI 图如下:
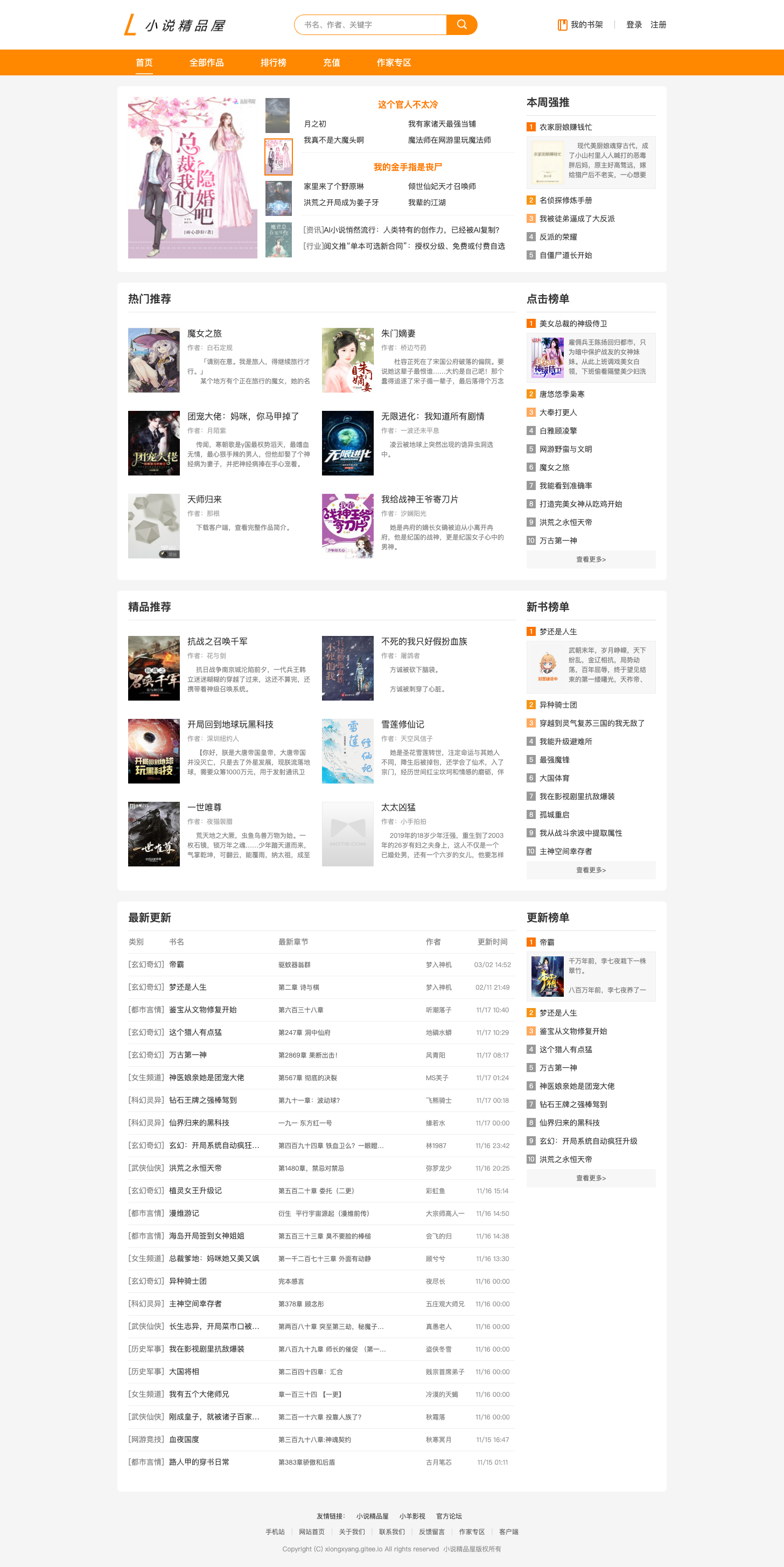
从上图可以看出首页包括 小说推荐(包括轮播图、周推、强推等)、新闻公告、点击榜、新书榜、更新榜(包括最新更新列表) 和 友情链接 6个内容区域的展示,所以我们需要开发 6 个相关的 API 查询接口以提供数据给前端。
首先,我们需要在 controller、service、service.impl 包下创建首页模块、新闻模块和小说模块的 API 控制器 Controller、业务服务类 Service 以及服务实现类 ServiceImpl。
注:首页是我们小说门户的入口,承载着我们系统很大一部分流量,并且内容不需要实时更新。所以首页相关内容的查询最好都做缓存处理。
# 首页小说推荐查询接口开发
首页小说推荐的数据主要保存在在数据库**home_book [首页小说推荐]**表中,该查询是一个从服务器取出资源的操作,所以该请求方法需要使用 GET 类型。具体实现步骤如下:
- 首先我们需要在
io.github.xxyopen.novel.manager包下创建首页推荐小说的缓存管理类如下:
/**
* 首页推荐小说 缓存管理类
*
* @author xiongxiaoyang
* @date 2022/5/12
*/
@Component
@RequiredArgsConstructor
public class HomeBookCacheManager {
private final HomeBookMapper homeBookMapper;
private final BookInfoMapper bookInfoMapper;
/**
* 查询首页小说推荐,并放入缓存中
*/
@Cacheable(cacheManager = CacheConsts.CAFFEINE_CACHE_MANAGER
, value = CacheConsts.HOME_BOOK_CACHE_NAME)
public List<HomeBookRespDto> listHomeBooks() {
// 从首页小说推荐表中查询出需要推荐的小说
List<HomeBook> homeBooks = homeBookMapper.selectList(null);
// 获取推荐小说ID列表
if (!CollectionUtils.isEmpty(homeBooks)) {
List<Long> bookIds = homeBooks.stream()
.map(HomeBook::getBookId)
.toList();
// 根据小说ID列表查询相关的小说信息列表
QueryWrapper<BookInfo> bookInfoQueryWrapper = new QueryWrapper<>();
bookInfoQueryWrapper.in("id", bookIds);
List<BookInfo> bookInfos = bookInfoMapper.selectList(bookInfoQueryWrapper);
// 组装 HomeBookRespDto 列表数据并返回
if(!CollectionUtils.isEmpty(bookInfos)){
Map<Long, BookInfo> bookInfoMap = bookInfos.stream()
.collect(Collectors.toMap(BookInfo::getId, Function.identity()));
return homeBooks.stream().map(v -> {
BookInfo bookInfo = bookInfoMap.get(v.getBookId());
HomeBookRespDto bookRespDto = new HomeBookRespDto();
bookRespDto.setBookId(v.getBookId());
bookRespDto.setBookName(bookInfo.getBookName());
bookRespDto.setPicUrl(bookInfo.getPicUrl());
bookRespDto.setAuthorName(bookInfo.getAuthorName());
bookRespDto.setBookDesc(bookInfo.getBookDesc());
return bookRespDto;
}).toList();
}
}
return Collections.emptyList();
}
}
该缓存管理类包含了一个查询首页小说推荐数据的方法,该方法执行数据库查询逻辑并进行简单的处理得到我们需要的数据格式并通过 @Cacheable 注解缓存起来。 该方法下次再被调用时会直接从缓存中拿取数据而不需要再一次查询数据库并处理,大大减轻了数据库的压力。
- 然后我们在首页模块业务类
HomeService中定义首页小说推荐查询的业务方法如下:
/**
* 首页模块 服务类
*
* @author xiongxiaoyang
* @date 2022/5/13
*/
public interface HomeService {
/**
* 查询首页小说推荐列表
*
* @return 首页小说推荐列表的 rest 响应结果
* */
RestResp<List<HomeBookRespDto>> listHomeBooks();
}
- 接着我们在首页模块业务实现类
HomeServiceImpl中实现HomeService中定义的抽象方法,通过调用HomeBookCacheManager的listHomeBooks方法获取到所需数据并返回:
/**
* 首页模块 服务实现类
*
* @author xiongxiaoyang
* @date 2022/5/13
*/
@Service
@RequiredArgsConstructor
public class HomeServiceImpl implements HomeService {
private final HomeBookCacheManager homeBookCacheManager;
@Override
public RestResp<List<HomeBookRespDto>> listHomeBooks() {
return RestResp.ok(homeBookCacheManager.listHomeBooks());
}
}
- 最后我们在首页模块的 API 控制器
HomeController中定义 GET 类型的查询接口,调用 service 中的相应业务方法获得首页小说推荐数据并返回给前端:
/**
* 首页模块 API 接口
*
* @author xiongxiaoyang
* @date 2022/5/12
*/
@RestController
@RequestMapping(ApiRouterConsts.API_FRONT_HOME_URL_PREFIX)
@RequiredArgsConstructor
public class HomeController {
private final HomeService homeService;
/**
* 首页小说推荐查询接口
* */
@GetMapping("books")
public RestResp<List<HomeBookRespDto>> listHomeBooks(){
return homeService.listHomeBooks();
}
}
# 登录注册相关接口开发
JWT(JSON Web Token)是一种开放的RFC 7519 (opens new window)行业标准方法,它定义了一种紧凑的、自包含的方式,用于作为 JSON 对象在各方之间安全地传输信息。该信息可以被验证和信任,因为它是数字签名的。服务端只生成和验证 JWT,客户端保存 JWT,所以 JWT 是无状态的。
由于 JWT 的无状态性,特别适用于分布式站点的单点登录(SSO)场景,已经成为了目前分布式服务权限控制解决方案的事实标准。我们 novel 项目是一个多系统并且后期会拓展为微服务架构的项目,所以使用 JWT 来实现登录认证。
JJWT (opens new window) 是一个在 JVM 和 Android 上创建和验证 JWT 非常易于使用和理解的库,JJWT 是完全基于 JWT、JWS、JWE、JWK 和 JWA RFC 规范的纯 Java 实现,并且在 Apache 2.0 许可条款下开源,目前在 JAVA 应用程序中广泛使用。novel 项目集成了该库以实现 JWT 的生成和验证。
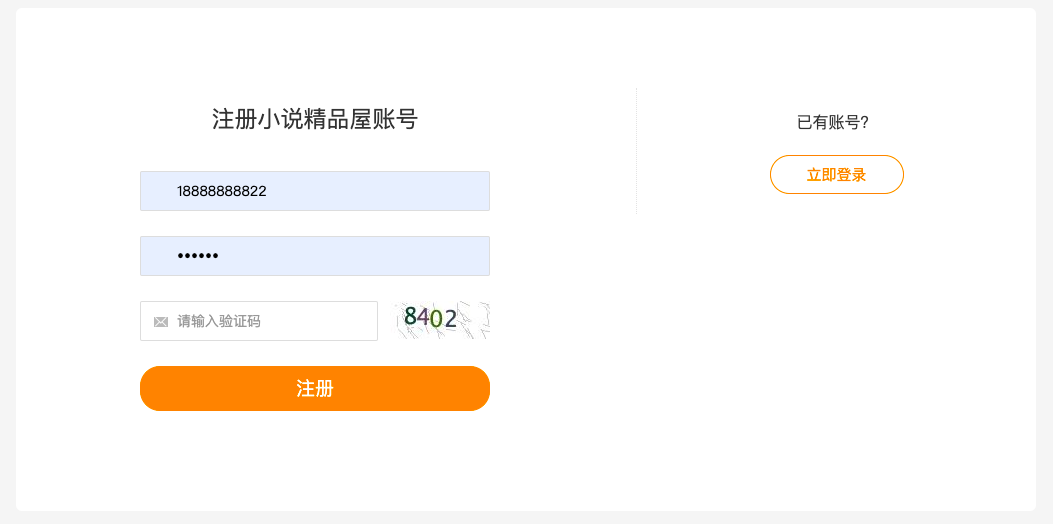
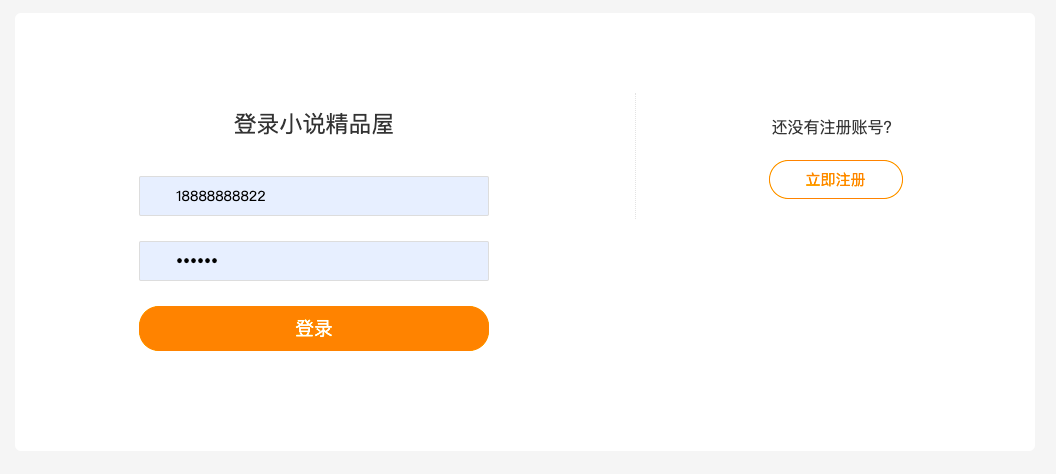
注册和登录的 UI 图如下:
# 获取图片验证码接口开发
从注册的 UI 图中可以看出我们需要一个图形验证码来防止用户利用机器人自动注册。该图形验证码由服务端生成,当用户申请注册时必须带上验证码,由服务端来校验验证码的有效性,只有验证码匹配才能允许用户注册。获取图片验证码接口开发步骤如下:
图形验证码属于一种图片资源,所以我们首先需要在 controller、service、service.impl 包下创建资源(Resource,处理图片/视频/文档等)模块的 API 控制器 Controller、业务服务类 Service 以及服务实现类 ServiceImpl。
接着我们需要在
io.github.xxyopen.novel.core.common.util包下创建图形验证码工具类来生成随机校验码和对应的 Base64 编码后的图片:
/**
* 图片验证码工具类
*
* @author xiongxiaoyang
* @date 2022/5/17
*/
@UtilityClass
public class ImgVerifyCodeUtils {
/**
* 随机产生只有数字的字符串
*/
private final String randNumber = "0123456789";
/**
* 图片宽
*/
private final int width = 100;
/**
* 图片高
*/
private final int height = 38;
private final Random random = new Random();
/**
* 获得字体
*/
private Font getFont() {
return new Font("Fixed", Font.PLAIN, 23);
}
/**
* 生成校验码图片
*/
public String genVerifyCodeImg(String verifyCode) throws IOException {
// BufferedImage类是具有缓冲区的Image类,Image类是用于描述图像信息的类
BufferedImage image = new BufferedImage(width, height, BufferedImage.TYPE_INT_BGR);
// 产生Image对象的Graphics对象,改对象可以在图像上进行各种绘制操作
Graphics g = image.getGraphics();
//图片大小
g.fillRect(0, 0, width, height);
//字体大小
//字体颜色
g.setColor(new Color(204, 204, 204));
// 绘制干扰线
// 干扰线数量
int lineSize = 40;
for (int i = 0; i <= lineSize; i++) {
drawLine(g);
}
// 绘制随机字符
drawString(g, verifyCode);
g.dispose();
//将图片转换成Base64字符串
ByteArrayOutputStream stream = new ByteArrayOutputStream();
ImageIO.write(image, "JPEG", stream);
return Base64.getEncoder().encodeToString(stream.toByteArray());
}
/**
* 绘制字符串
*/
private void drawString(Graphics g, String verifyCode) {
for (int i = 1; i <= verifyCode.length(); i++) {
g.setFont(getFont());
g.setColor(new Color(random.nextInt(101), random.nextInt(111), random
.nextInt(121)));
g.translate(random.nextInt(3), random.nextInt(3));
g.drawString(String.valueOf(verifyCode.charAt(i - 1)), 13 * i, 23);
}
}
/**
* 绘制干扰线
*/
private void drawLine(Graphics g) {
int x = random.nextInt(width);
int y = random.nextInt(height);
int xl = random.nextInt(13);
int yl = random.nextInt(15);
g.drawLine(x, y, x + xl, y + yl);
}
/**
* 获取随机的校验码
*/
public String getRandomVerifyCode(int num) {
int randNumberSize = randNumber.length();
StringBuilder verifyCode = new StringBuilder();
for (int i = 0; i < num; i++) {
String rand = String.valueOf(randNumber.charAt(random.nextInt(randNumberSize)));
verifyCode.append(rand);
}
return verifyCode.toString();
}
}
- 然后,我们在
io.github.xxyopen.novel.manager包下创建验证码管理类,用于生成、校验和删除验证码(不限于图形验证码):
/**
* 验证码 管理类
*
* @author xiongxiaoyang
* @date 2022/5/12
*/
@Component
@RequiredArgsConstructor
@Slf4j
public class VerifyCodeManager {
private final StringRedisTemplate stringRedisTemplate;
/**
* 生成图形验证码,并放入 Redis 中
*/
public String genImgVerifyCode(String sessionId) throws IOException {
String verifyCode = ImgVerifyCodeUtils.getRandomVerifyCode(4);
String img = ImgVerifyCodeUtils.genVerifyCodeImg(verifyCode);
stringRedisTemplate.opsForValue().set(CacheConsts.IMG_VERIFY_CODE_CACHE_KEY + sessionId
, verifyCode, Duration.ofMinutes(5));
return img;
}
/**
* 校验图形验证码
*/
public boolean imgVerifyCodeOk(String sessionId, String verifyCode) {
return Objects.equals(
stringRedisTemplate.opsForValue().get(CacheConsts.IMG_VERIFY_CODE_CACHE_KEY + sessionId)
, verifyCode);
}
/**
* 从 Redis 中删除验证码
*/
public void removeImgVerifyCode(String sessionId) {
stringRedisTemplate.delete(CacheConsts.IMG_VERIFY_CODE_CACHE_KEY + sessionId);
}
注:我们在保存验证码的时候需要一个全局唯一的 sessionId 字符串用于标识该验证码属于哪个浏览器会话,该 sessionId 会在验证码返回给前端的时候一并返回,在用户提交注册的时候,该 sessionId 会和验证码一起提交用于校验
- 接着,我们在资源模块业务类
ResourceService中定义获取图片验证码的业务方法如下:
/**
* 获取图片验证码
*
* @throws IOException 验证码图片生成失败
* @return Base64编码的图片
*/
RestResp<ImgVerifyCodeRespDto> getImgVerifyCode() throws IOException;
- 接着,我们在资源模块业务实现类
ResourceServiceImpl中实现ResourceService中定义的抽象方法,调用VerifyCodeManager中获取图形验证码方法并返回结果:
@Override
public RestResp<ImgVerifyCodeRespDto> getImgVerifyCode() throws IOException {
String sessionId = IdWorker.get32UUID();
return RestResp.ok(ImgVerifyCodeRespDto.builder()
.sessionId(sessionId)
.img(verifyCodeManager.genImgVerifyCode(sessionId))
.build());
}
- 最后,我们在资源模块的 API 控制器
ResourceController中定义 GET 类型的查询接口,调用 service 中的相应业务方法获得图形验证码数据并返回给前端:
/**
* 获取图片验证码接口
*/
@GetMapping("img_verify_code")
public RestResp<ImgVerifyCodeRespDto> getImgVerifyCode() throws IOException {
return resourceService.getImgVerifyCode();
}
# 注册接口开发
用户注册需要在在数据库**user_info [用户信息]**表中插入一条用户数据,是一个在服务器新建资源的操作,所以该请求方法需要使用 POST 类型。具体实现步骤如下:
- 首先我们在配置文件
application.yml中定义 JWT 相关配置:
# 项目配置
novel:
# JWT 密钥
jwt:
secret: E66559580A1ADF48CDD928516062F12E
注:目前只有 JWT 密钥的配置,后期会拓展过期时间等其他配置
- 然后,我们在
io.github.xxyopen.novel.core.util包下创建 JWT 工具类,用于 JWT 的生成和解析:
/**
* JWT 工具类
*
* @author xiongxiaoyang
* @date 2022/5/17
*/
@ConditionalOnProperty("novel.jwt.secret")
@Component
@Slf4j
public class JwtUtils {
/**
* 注入JWT加密密钥
*/
@Value("${novel.jwt.secret}")
private String secret;
/**
* 定义系统标识头常量
*/
private static final String HEADER_SYSTEM_KEY = "systemKeyHeader";
/**
* 根据用户 ID 生成 JWT
* @param uid 用户 ID
* @param systemKey 系统标识
* @return JWT
*/
public String generateToken(Long uid, String systemKey) {
return Jwts.builder()
.setHeaderParam(HEADER_SYSTEM_KEY, systemKey)
.setSubject(uid.toString())
.signWith(Keys.hmacShaKeyFor(secret.getBytes(StandardCharsets.UTF_8)))
.compact();
}
/**
* 解析 JWT 返回用户 ID
* @param token JWT
* @param systemKey 系统标识
* @return 用户 ID
*/
public Long parseToken(String token, String systemKey) {
Jws<Claims> claimsJws;
try {
claimsJws = Jwts.parserBuilder()
.setSigningKey(Keys.hmacShaKeyFor(secret.getBytes(StandardCharsets.UTF_8)))
.build()
.parseClaimsJws(token);
// OK, we can trust this JWT
// 判断该 JWT 是否属于指定系统
if (Objects.equals(claimsJws.getHeader().get(HEADER_SYSTEM_KEY), systemKey)) {
return Long.parseLong(claimsJws.getBody().getSubject());
}
} catch (JwtException e) {
log.warn("JWT解析失败:{}", token);
// don't trust the JWT!
}
return null;
}
}
- 接着我们需要在用户模块业务类
UserService中定义注册的业务方法如下:
/**
* 用户注册
*
* @param dto 注册参数
* @return JWT
*/
RestResp<UserRegisterRespDto> register(UserRegisterReqDto dto);
- 接着我们在用户模块业务实现类
UserServiceImpl中实现UserService中定义的抽象方法,对验证码、手机号进行校验。校验成功,则保存用户信息到数据库,并删除验证码和使用 JWT 工具类生成 JWT 字符串返回;校验失败,则返回相应的错误码给前端,具体代码如下:
@Override
public RestResp<UserRegisterRespDto> register(UserRegisterReqDto dto) {
// 校验图形验证码是否正确
if (!verifyCodeManager.imgVerifyCodeOk(dto.getSessionId(), dto.getVelCode())) {
// 图形验证码校验失败
throw new BusinessException(ErrorCodeEnum.USER_VERIFY_CODE_ERROR);
}
// 校验手机号是否已注册
QueryWrapper<UserInfo> queryWrapper = new QueryWrapper<>();
queryWrapper.eq(DatabaseConsts.UserInfoTable.COLUMN_USERNAME, dto.getUsername())
.last(DatabaseConsts.SqlEnum.LIMIT_1.getSql());
if (userInfoMapper.selectCount(queryWrapper) > 0) {
// 手机号已注册
throw new BusinessException(ErrorCodeEnum.USER_NAME_EXIST);
}
// 注册成功,保存用户信息
UserInfo userInfo = new UserInfo();
userInfo.setPassword(DigestUtils.md5DigestAsHex(dto.getPassword().getBytes(StandardCharsets.UTF_8)));
userInfo.setUsername(dto.getUsername());
userInfo.setNickName(dto.getUsername());
userInfo.setCreateTime(LocalDateTime.now());
userInfo.setUpdateTime(LocalDateTime.now());
userInfo.setSalt("0");
userInfoMapper.insert(userInfo);
// 删除验证码
verifyCodeManager.removeImgVerifyCode(dto.getSessionId());
// 生成JWT 并返回
return RestResp.ok(
UserRegisterRespDto.builder()
.token(jwtUtils.generateToken(userInfo.getId(), SystemConfigConsts.NOVEL_FRONT_KEY))
.uid(userInfo.getId())
.build()
);
}
- 最后,我们在用户模块 API 控制器
UserController中定义 POST 类型的注册接口,调用用户模块 service 中的相应业务方法注册用户:
/**
* 用户注册接口
*/
@PostMapping("register")
public RestResp<UserRegisterRespDto> register(@Valid @RequestBody UserRegisterReqDto dto) {
return userService.register(dto);
}
# 登录接口开发
用户登录是一个特殊接口,不是单独请求一个资源,而是对于用户信息验证,创建一个 JWT,而且登录提交的数据中还包含敏感数据(密码)。URL 带的参数必须无敏感信息或符合安全要求,所以我们需要定义 POST 类型的接口来处理登录请求。具体实现步骤如下:
- 首先我们需要在用户模块业务类
UserService中定义登录的业务方法如下:
/**
* 用户登录
*
* @param dto 登录参数
* @return JWT + 昵称
*/
RestResp<UserLoginRespDto> login(UserLoginReqDto dto);
- 接着我们在用户模块业务实现类
UserServiceImpl中实现UserService中定义的抽象方法,对登录用户名密码进行校验。校验通过,则生成 JWT 字符串返回;校验失败,则返回对应的错误码:
@Override
public RestResp<UserLoginRespDto> login(UserLoginReqDto dto) {
// 查询用户信息
QueryWrapper<UserInfo> queryWrapper = new QueryWrapper<>();
queryWrapper.eq(DatabaseConsts.UserInfoTable.COLUMN_USERNAME, dto.getUsername())
.last(DatabaseConsts.SqlEnum.LIMIT_1.getSql());
UserInfo userInfo = userInfoMapper.selectOne(queryWrapper);
if (Objects.isNull(userInfo)) {
// 用户不存在
throw new BusinessException(ErrorCodeEnum.USER_ACCOUNT_NOT_EXIST);
}
// 判断密码是否正确
if (!Objects.equals(userInfo.getPassword()
, DigestUtils.md5DigestAsHex(dto.getPassword().getBytes(StandardCharsets.UTF_8)))) {
// 密码错误
throw new BusinessException(ErrorCodeEnum.USER_PASSWORD_ERROR);
}
// 登录成功,生成JWT并返回
return RestResp.ok(UserLoginRespDto.builder()
.token(jwtUtils.generateToken(userInfo.getId(), SystemConfigConsts.NOVEL_FRONT_KEY))
.uid(userInfo.getId())
.nickName(userInfo.getNickName()).build());
}
- 最后,我们在用户模块 API 控制器
UserController中定义 POST 类型的登录接口,调用用户模块 service 中的相应业务方法:
/**
* 用户登录接口
*/
@PostMapping("login")
public RestResp<UserLoginRespDto> login(@Valid @RequestBody UserLoginReqDto dto) {
return userService.login(dto);
}
# 小说详情页相关接口开发
小说详情页 UI 图如下:
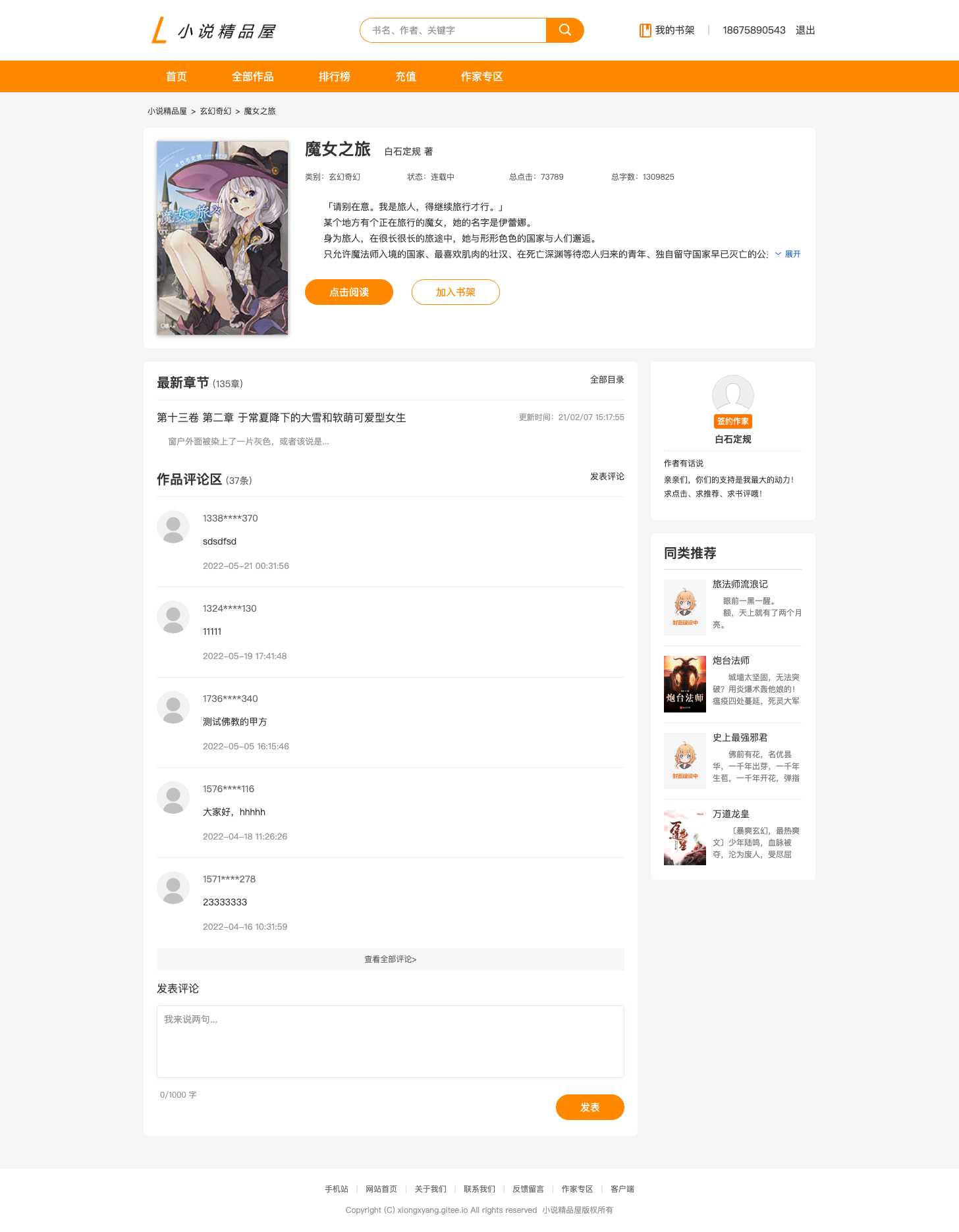
从上图可以看出小说详情页包括 小说信息(包括作家信息)、最新章节、作品评论、同类推荐四个内容区域的展示,而评论区还包含了评论发表、评论修改和评论删除的功能。所以我们需要开发与小说详情页相关的 4 个 API 查询接口、1 个 API 增加接口、1 个 API 修改接口和 1 个 API 删除接口提供给前端。
# 小说评论发表接口开发
评论发表需要在数据库**book_comment [小说评论]**表中插入一条评论数据,是一个在服务器新建资源的操作,所以该请求方法需要使用 POST 类型。具体实现步骤如下:
- 首先我们需要在小说模块业务类
BookService中定义发表评论的业务方法如下:
/**
* 发表评论
*
* @param dto 评论相关 DTO
* @return void
*/
RestResp<Void> saveComment(UserCommentReqDto dto);
- 接着我们在小说模块业务实现类
BookServiceImpl中实现BookService中定义的抽象方法,将用户对小说的评论数据保存到数据库中:
@Override
public RestResp<Void> saveComment(UserCommentReqDto dto) {
// 校验用户是否已发表评论
QueryWrapper<BookComment> queryWrapper = new QueryWrapper<>();
queryWrapper.eq(DatabaseConsts.BookCommentTable.COLUMN_USER_ID,dto.getUserId())
.eq(DatabaseConsts.BookCommentTable.COLUMN_BOOK_ID,dto.getBookId());
if(bookCommentMapper.selectCount(queryWrapper) > 0){
// 用户已发表评论
return RestResp.fail(ErrorCodeEnum.USER_COMMENTED);
}
BookComment bookComment = new BookComment();
bookComment.setBookId(dto.getBookId());
bookComment.setUserId(dto.getUserId());
bookComment.setCommentContent(dto.getCommentContent());
bookComment.setCreateTime(LocalDateTime.now());
bookComment.setUpdateTime(LocalDateTime.now());
bookCommentMapper.insert(bookComment);
return RestResp.ok();
}
注:保存评论之前我们需要对用户是否已发表评论进行校验,每个用户只能对同一本书发表一条评论。
- 最后,由于发表评论的行为属于用户(需要校验登录权限),所以我们在用户模块 API 控制器
UserController中定义 POST 类型的增加接口,调用小说模块 service 中的相应业务方法保存小说评论数据:
/**
* 发表评论接口
*/
@PostMapping("comment")
public RestResp<Void> comment(@Valid @RequestBody UserCommentReqDto dto) {
dto.setUserId(UserHolder.getUserId());
return bookService.saveComment(dto);
}
# 小说评论修改接口开发
评论修改需要更新数据库**book_comment [小说评论]**表中的评论数据,是一个在服务器更新资源的操作,所以该请求方法需要使用 PUT 类型。具体实现步骤如下:
- 首先我们需要在小说模块业务类
BookService中定义修改评论的业务方法如下:
/**
* 修改评论
* @param userId 用户ID
* @param id 评论ID
* @param content 修改后的评论内容
* @return void
* */
RestResp<Void> updateComment(Long userId, Long id, String content);
- 接着我们在小说模块业务实现类
BookServiceImpl中实现BookService中定义的抽象方法,更新数据表中的评论数据:
@Override
public RestResp<Void> updateComment(Long userId, Long id, String content) {
QueryWrapper<BookComment> queryWrapper = new QueryWrapper<>();
queryWrapper.eq(DatabaseConsts.CommonColumnEnum.ID.getName(), id)
.eq(DatabaseConsts.BookCommentTable.COLUMN_USER_ID,userId);
BookComment bookComment = new BookComment();
bookComment.setCommentContent(content);
bookCommentMapper.update(bookComment,queryWrapper);
return RestResp.ok();
}
注:用户只能更新自己的小说评论,所以更新评论表中数据的 where 条件不但需要小说ID还需要加上用户ID
- 最后,由于修改评论的行为属于用户(需要校验登录权限),所以我们在用户模块 API 控制器
UserController中定义 PUT 类型的修改接口,调用小说模块 service 中的相应业务方法来更新小说评论数据:
/**
* 修改评论接口
*/
@PutMapping("comment/{id}")
public RestResp<Void> updateComment(@PathVariable Long id, String content) {
return bookService.updateComment(UserHolder.getUserId(), id, content);
}
# 小说评论删除接口开发
评论删除需要删除数据库**book_comment [小说评论]**表中的评论数据,是一个从服务器删除资源的操作,所以该请求方法需要使用 DELETE 类型。具体实现步骤如下:
- 首先我们需要在小说模块业务类
BookService中定义删除评论的业务方法如下:
/**
* 删除评论
* @param userId 评论用户ID
* @param commentId 评论ID
* @return void
* */
RestResp<Void> deleteComment(Long userId, Long commentId);
- 接着我们在小说模块业务实现类
BookServiceImpl中实现BookService中定义的抽象方法,删除数据表中的评论数据:
@Override
public RestResp<Void> deleteComment(Long userId, Long commentId) {
QueryWrapper<BookComment> queryWrapper = new QueryWrapper<>();
queryWrapper.eq(DatabaseConsts.CommonColumnEnum.ID.getName(), commentId)
.eq(DatabaseConsts.BookCommentTable.COLUMN_USER_ID,userId);
bookCommentMapper.delete(queryWrapper);
return RestResp.ok();
}
注:用户只能删除自己的小说评论,所以删除评论表中数据的 where 条件不但需要小说ID还需要加上用户ID
- 最后,由于删除评论的行为属于用户(需要校验登录权限),所以我们在用户模块 API 控制器
UserController中定义 DELETE 类型的删除接口,调用小说模块 service 中的相应业务方法来删除小说评论数据:
/**
* 删除评论接口
*/
@DeleteMapping("comment/{id}")
public RestResp<Void> deleteComment(@PathVariable Long id) {
return bookService.deleteComment(UserHolder.getUserId(), id);
}
# 小说最新评论列表查询接口开发
最新评论列表查询需要查询数据库**book_comment [小说评论]**表中的评论数据,是一个从服务器取出资源的操作,所以该请求方法需要使用 GET 类型。具体实现步骤如下:
- 首先我们需要在小说模块业务类
BookService中定义查询最新评论列表的业务方法如下:
/**
* 小说最新评论查询
*
* @param bookId 小说ID
* @return 小说最新评论数据
*/
RestResp<BookCommentRespDto> listNewestComments(Long bookId);
- 接着我们在小说模块业务实现类
BookServiceImpl中实现BookService中定义的抽象方法,查询数据表中的最新评论列表数据:
@Override
public RestResp<BookCommentRespDto> listNewestComments(Long bookId) {
// 查询评论总数
QueryWrapper<BookComment> commentCountQueryWrapper = new QueryWrapper<>();
commentCountQueryWrapper.eq(DatabaseConsts.BookCommentTable.COLUMN_BOOK_ID, bookId);
Long commentTotal = bookCommentMapper.selectCount(commentCountQueryWrapper);
BookCommentRespDto bookCommentRespDto = BookCommentRespDto.builder().commentTotal(commentTotal).build();
if (commentTotal > 0) {
// 查询最新的评论列表
QueryWrapper<BookComment> commentQueryWrapper = new QueryWrapper<>();
commentQueryWrapper.eq(DatabaseConsts.BookCommentTable.COLUMN_BOOK_ID, bookId)
.orderByDesc(DatabaseConsts.CommonColumnEnum.CREATE_TIME.getName())
.last(DatabaseConsts.SqlEnum.LIMIT_5.getSql());
List<BookComment> bookComments = bookCommentMapper.selectList(commentQueryWrapper);
// 查询评论用户信息,并设置需要返回的评论用户名
List<Long> userIds = bookComments.stream().map(BookComment::getUserId).toList();
List<UserInfo> userInfos = userDaoManager.listUsers(userIds);
Map<Long, String> userInfoMap = userInfos.stream().collect(Collectors.toMap(UserInfo::getId, UserInfo::getUsername));
List<BookCommentRespDto.CommentInfo> commentInfos = bookComments.stream()
.map(v -> BookCommentRespDto.CommentInfo.builder()
.id(v.getId())
.commentUserId(v.getUserId())
.commentUser(userInfoMap.get(v.getUserId()))
.commentContent(v.getCommentContent())
.commentTime(v.getCreateTime()).build()).toList();
bookCommentRespDto.setComments(commentInfos);
} else {
bookCommentRespDto.setComments(Collections.emptyList());
}
return RestResp.ok(bookCommentRespDto);
}
- 最后,我们在小说模块 API 控制器
BookController中定义 GET 类型的查询接口,调用 service 中的相应业务方法来查询小说最新评论列表数据:
/**
* 小说最新评论查询接口
*/
@GetMapping("comment/newest_list")
public RestResp<BookCommentRespDto> listNewestComments(Long bookId) {
return bookService.listNewestComments(bookId);
}
- 因为小说评论的用户名(手机号)属于敏感数据,我们不应该直接返回给前端。所以我们还需要定义一个 JSON 序列化器在 Spring MVC 序列化我们返回的 Java 对象为 JSON 字符串时格式化一下用户名,隐藏中间的 4 位数字为
****。代码如下:
/**
* 用户名序列化器(敏感信息,不应该在页面上完全显示)
*
* @author xiongxiaoyang
* @date 2022/5/20
*/
public class UsernameSerializer extends JsonSerializer<String> {
@Override
public void serialize(String s, JsonGenerator jsonGenerator, SerializerProvider serializerProvider) throws IOException {
jsonGenerator.writeString(s.substring(0,4) + "****" + s.substring(8));
}
}
/**
* 小说评论 响应DTO
* @author xiongxiaoyang
* @date 2022/5/17
*/
@Data
@Builder
public class BookCommentRespDto {
private Long commentTotal;
private List<CommentInfo> comments;
@Data
@Builder
public static class CommentInfo {
private Long id;
private String commentContent;
@JsonSerialize(using = UsernameSerializer.class)
private String commentUser;
private Long commentUserId;
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss")
private LocalDateTime commentTime;
}
}