# 项目优化
# 使用策略模式重构多系统环境下的用户认证授权
# 需求
小说精品屋由前台门户系统、作家后台管理系统、平台后台管理系统和爬虫管理系统以及后面可能会扩展的漫画系统和视频系统等多个子系统构成,是一个复杂的多系统环境。平台端的后台管理系统和爬虫管理系统账号是独立的,用户端其它子系统要求统一账号登录。那么我们应该如何设计才能统一对这些系统进行认证授权呢 ?
# 实现思路
我们提供平台管理后台、爬虫管理后台和单点登录三个登录入口,前端在每个登录入口登录成功之后都会获得后端返回的 token,这个时候需要分别保存起来, 在请求相应系统的后端接口时,通过请求头携带上相应的 token。
后端需要配置一个统一的拦截器,根据请求的 URI 识别出相应系统类型,并对这些 token 进行解析得到 userId。这个时候就可以根据用户来鉴权,如果用户有权访问,则放行。否则,返回一个相应的错误码给前端。具体代码如下:
public class AuthInterceptor implements HandlerInterceptor {
private final JwtUtils jwtUtils;
private final ObjectMapper objectMapper;
@SuppressWarnings("NullableProblems")
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
// 校验登录 token
String token = request.getHeader(SystemConfigConsts.HTTP_AUTH_HEADER_NAME);
if (!Objects.isNull(token)) {
String requestUri = request.getRequestURI();
if (requestUri.contains(ApiRouterConsts.API_FRONT_URL_PREFIX)) {
// 校验门户系统用户权限
Long userId = jwtUtils.parseToken(token, SystemConfigConsts.NOVEL_FRONT_KEY);
if (!Objects.isNull(userId)) {
// TODO 查询用户信息并校验账号状态是否正常
// TODO 其它权限校验
// 认证成功
return HandlerInterceptor.super.preHandle(request, response, handler);
}
}else if (requestUri.contains(ApiRouterConsts.API_AUTHOR_URL_PREFIX)){
// TODO 校验作家后台管理系统用户权限
}else if (requestUri.contains(ApiRouterConsts.API_ADMIN_URL_PREFIX)){
// TODO 校验平台后台管理系统用户权限
}
//。。。更多系统权限校验
// 完整实现可能至少几百行的代码
}
response.setCharacterEncoding(StandardCharsets.UTF_8.name());
response.setContentType(MediaType.APPLICATION_JSON_VALUE);
response.getWriter().write(objectMapper.writeValueAsString(RestResp.fail(ErrorCodeEnum.USER_LOGIN_EXPIRED)));
return false;
}
}
此时,可以简单的实现基本的权限拦截功能。但是因为所有系统的认证授权逻辑都在这一个方法中,代码及其臃肿难以维护。每当某一系统授权逻辑发生变化或者新增加了一个子系统,都需要修改此处的代码。修改之前不但必须先完全理解这一大段代码,正确定位到需要修改的位置,而且极其容易影响到不相干的其它系统认证授权功能。久而久之就没有人愿意维护这部分代码了。为了解决这个问题,下面我们使用策略模式来重构该功能。
# 策略模式定义
策略模式定义了算法族,分别封装起来,让它们之间可以互相替换,此模式让算法的变化独立于使用算法的客户。
策略模式的核心在于封装变化,在我们系统中就是定义多个不同系统的认证授权策略(算法族),分别封装成独立的类。拦截器(客户)在运行时根据具体的请求 URI 来动态调用相应系统的认证授权算法。当某一系统的认证授权逻辑发生变化或增加新的子系统时,我们只需要修改或增加相应的策略类,而不会影响到其它的策略类(子系统)和客户(拦截器)。
# 重构步骤
- 在
io.github.xxyopen.novel.core.auth包下创建 AuthStrategy 接口,该接口定义了一个默认的方法实现用户端所有子系统都需要的统一账号认证逻辑和一个封装各个系统独立认证授权逻辑的待实现方法(例如,作家管理系统还需要验证作家账号是否存在和作家状态是否正常):
/**
* 策略模式实现用户认证授权功能
*
* @author xiongxiaoyang
* @date 2022/5/18
*/
public interface AuthStrategy {
/**
* 用户认证授权
*
* @param token 登录 token
* @param requestUri 请求的 URI
* @throws BusinessException 认证失败则抛出业务异常
*/
void auth(String token, String requestUri) throws BusinessException;
/**
* 前台多系统单点登录统一账号认证(门户系统、作家系统以及后面会扩展的漫画系统和视频系统等)
*
* @param jwtUtils jwt 工具
* @param userInfoCacheManager 用户缓存管理对象
* @param token token 登录 token
* @return 用户ID
*/
default Long authSSO(JwtUtils jwtUtils, UserInfoCacheManager userInfoCacheManager,
String token) {
if (!StringUtils.hasText(token)) {
// token 为空
throw new BusinessException(ErrorCodeEnum.USER_LOGIN_EXPIRED);
}
Long userId = jwtUtils.parseToken(token, SystemConfigConsts.NOVEL_FRONT_KEY);
if (Objects.isNull(userId)) {
// token 解析失败
throw new BusinessException(ErrorCodeEnum.USER_LOGIN_EXPIRED);
}
UserInfoDto userInfo = userInfoCacheManager.getUser(userId);
if (Objects.isNull(userInfo)) {
// 用户不存在
throw new BusinessException(ErrorCodeEnum.USER_ACCOUNT_NOT_EXIST);
}
// 设置 userId 到当前线程
UserHolder.setUserId(userId);
// 返回 userId
return userId;
}
}
- 接着在该包下创建各个系统的认证授权策略类,实现上述的 AuthStrategy 接口:
/**
* 前台门户系统 认证授权策略
*
* @author xiongxiaoyang
* @date 2022/5/18
*/
@Component
@RequiredArgsConstructor
public class FrontAuthStrategy implements AuthStrategy {
private final JwtUtils jwtUtils;
private final UserInfoCacheManager userInfoCacheManager;
@Override
public void auth(String token, String requestUri) throws BusinessException {
// 统一账号认证
authSSO(jwtUtils, userInfoCacheManager, token);
}
}
/**
* 作家后台管理系统 认证授权策略
*
* @author xiongxiaoyang
* @date 2022/5/18
*/
@Component
@RequiredArgsConstructor
public class AuthorAuthStrategy implements AuthStrategy {
private final JwtUtils jwtUtils;
private final UserInfoCacheManager userInfoCacheManager;
private final AuthorInfoCacheManager authorInfoCacheManager;
/**
* 不需要进行作家权限认证的 URI
*/
private static final List<String> EXCLUDE_URI = List.of(
ApiRouterConsts.API_AUTHOR_URL_PREFIX + "/register",
ApiRouterConsts.API_AUTHOR_URL_PREFIX + "/status"
);
@Override
public void auth(String token, String requestUri) throws BusinessException {
// 统一账号认证
Long userId = authSSO(jwtUtils, userInfoCacheManager, token);
if (EXCLUDE_URI.contains(requestUri)) {
// 该请求不需要进行作家权限认证
return;
}
// 作家权限校验
AuthorInfoDto authorInfo = authorInfoCacheManager.getAuthor(userId);
if (Objects.isNull(authorInfo)) {
// 作家账号不存在,无权访问作家专区
throw new BusinessException(ErrorCodeEnum.USER_UN_AUTH);
}
// 设置作家ID到当前线程
UserHolder.setAuthorId(authorInfo.getId());
}
}
/**
* 平台后台管理系统 认证授权策略
*
* @author xiongxiaoyang
* @date 2022/5/18
*/
@Component
@RequiredArgsConstructor
public class AdminAuthStrategy implements AuthStrategy {
@Override
public void auth(String token, String requestUri) throws BusinessException {
// TODO 平台后台 token 校验
}
}
- 最后在拦截器中根据请求 URI 动态调用相应策略:
/**
* 认证授权 拦截器
* 为了注入其它的 Spring beans,需要通过 @Component 注解将该拦截器注册到 Spring 上下文
*
* @author xiongxiaoyang
* @date 2022/5/18
*/
@Component
@RequiredArgsConstructor
public class AuthInterceptor implements HandlerInterceptor {
private final Map<String,AuthStrategy> authStrategy;
private final ObjectMapper objectMapper;
@SuppressWarnings("NullableProblems")
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
// 获取登录 JWT
String token = request.getHeader(SystemConfigConsts.HTTP_AUTH_HEADER_NAME);
// 获取请求的 URI
String requestUri = request.getRequestURI();
// 根据请求的 URI 得到认证策略
String subUri = requestUri.substring(ApiRouterConsts.API_URL_PREFIX.length() + 1);
String systemName = subUri.substring(0,subUri.indexOf("/"));
String authStrategyName = String.format("%sAuthStrategy",systemName);
// 开始认证
try {
authStrategy.get(authStrategyName).auth(token);
return HandlerInterceptor.super.preHandle(request, response, handler);
}catch (BusinessException exception){
// 认证失败
response.setCharacterEncoding(StandardCharsets.UTF_8.name());
response.setContentType(MediaType.APPLICATION_JSON_VALUE);
response.getWriter().write(objectMapper.writeValueAsString(RestResp.fail(exception.getErrorCodeEnum())));
return false;
}
}
@SuppressWarnings("NullableProblems")
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception {
// 清理当前线程保存的用户数据
UserHolder.clear();
HandlerInterceptor.super.postHandle(request, response, handler, modelAndView);
}
}
# 使用装饰者模式解决表单形式传参的 XSS 攻击
# XSS 攻击定义
跨站脚本攻击(XSS),是最普遍的 Web 应用安全漏洞。能够使得攻击者嵌入恶意脚本代码到正常用户会访问到的页面中,当正常用户访问该页面时,则可导致嵌入的恶意脚本代码的执行,从而达到恶意攻击用户的目的。
例如,在 novel 项目中,如果没有预防 XSS 攻击的话。恶意用户进入到我们小说评论区,发表如下评论:
<script>
// 获取当前登录用户的认证 token
token = localStorage.getItem('Authorization');
// TODO 通过 ajax 请求发送该 token 到恶意用户的指定服务器
</script>
当其他正常用户登录成功进入到小说评论区后,会自动执行上述的 javascript 脚本,自己的登录 token 会被发送到攻击者的服务器上。攻击者拿到该 token 后即可利用该 token 来冒充正常用户进行一系列例如资金转账等危险操作。
攻击者还可以利用该漏洞在我们系统中插入恶意内容(例如广告)、重定向用户(重定向到黄赌毒网站)等。
注:人们经常将跨站脚本攻击(Cross Site Scripting)缩写为 CSS,但这会与层叠样式表(Cascading Style Sheets,CSS)的缩写混淆。因此,有人将跨站脚本攻击缩写为 XSS。
# 装饰者模式定义
动态将责任附加到对象上。想要扩展功能,装饰者提供有别于继承的另一种选择。
装饰者可以在被装饰者的行为前面与/或后面加上自己的行为,甚至将被装饰者的行为整个取代掉,而达到特定的目的。
Spring MVC 是通过 HttpServletRequest 的 getParameterValues 方法来获取用户端的请求参数并绑定到我们 @RequestMapping 方法定义的对象上。所以我们可以装饰 HttpServletRequest 对象,在 getParameterValues 方法里加上自己的行为(对请求参数值里面的特殊字符进行转义)来解决 XSS 攻击。
由于 Servlet Api 提供了 HttpServletRequest 接口的便捷实现 HttpServletRequestWrapper 类,该类已经实现了装饰者模式,我们直接继承该类并重写里面的 getParameterValues 方法即可。
# 实现步骤
- 新建 XssHttpServletRequestWrapper 装饰者类继承 HttpServletRequestWrapper 类,并重写 getParameterValues 方法,对里面字符串的特殊字符进行转义:
public class XssHttpServletRequestWrapper extends HttpServletRequestWrapper {
private static final Map<String,String> REPLACE_RULE = new HashMap<>();
static {
REPLACE_RULE.put("<", "<");
REPLACE_RULE.put(">", ">");
}
public XssHttpServletRequestWrapper(HttpServletRequest request) {
super(request);
}
@Override
public String[] getParameterValues(String name) {
String[] values = super.getParameterValues(name);
if (values != null) {
int length = values.length;
String[] escapeValues = new String[length];
for (int i = 0; i < length; i++) {
escapeValues[i] = values[i];
int index = i;
REPLACE_RULE.forEach((k, v)-> escapeValues[index] = escapeValues[index].replaceAll(k, v));
}
return escapeValues;
}
return new String[0];
}
}
- 新建 XssFilter 过滤器,使用 XssHttpServletRequestWrapper 装饰者对象替换掉 HttpServletRequest 被装饰者对象:
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
XssHttpServletRequestWrapper xssRequest = new XssHttpServletRequestWrapper((HttpServletRequest) servletRequest);
filterChain.doFilter(xssRequest, servletResponse);
}
# 一行代码解决 JSON 形式传参的 XSS 攻击
# 问题
前后端分离项目,对于 POST 和 PUT 类型的请求方法,后端基本都是通过 @RequestBody 注解接收 application/json 格式的请求数据,所以以前通过过滤器 + 装饰器 HttpServletRequestWrapper 来解决 XSS 攻击的方式并不适用。在 Spring Boot 中,我们可以通过配置全局的 Json 反序列化器转义特殊字符来解决 XSS 攻击。
# 实现代码
/**
* JSON 全局反序列化器
*
* @author xiongxiaoyang
* @date 2022/5/21
*/
@JsonComponent
public class GlobalJsonDeserializer {
/**
* 字符串反序列化器
* 过滤特殊字符,解决 XSS 攻击
*/
public static class StringDeserializer extends JsonDeserializer<String> {
@Override
public String deserialize(JsonParser jsonParser, DeserializationContext deserializationContext) throws IOException, JacksonException {
// 实际代码就这一行
return jsonParser.getValueAsString()
.replace("<", "<")
.replace(">", ">");
}
}
}
# 集成 Elasticsearch 8,实现搜索引擎动态切换
在 application.yml 中增加
spring.elasticsearch.enable配置项用来控制 Elasticsearch 搜索引擎功能是否开启:
spring:
elasticsearch:
# 是否开启 elasticsearch 搜索引擎功能:true-开启 false-不开启
enable: false
- 新建搜索服务类:
/**
* 搜索 服务类
*
* @author xiongxiaoyang
* @date 2022/5/23
*/
public interface SearchService {
/**
* 小说搜索
*
* @param condition 搜索条件
* @return 搜索结果
*/
RestResp<PageRespDto<BookInfoRespDto>> searchBooks(BookSearchReqDto condition);
}
- 新建
数据库搜索服务实现类,实现从数据库中检索小说的业务逻辑,由配置项spring.elasticsearch.enable控制当 elasticsearch 关闭时生效:
/**
* 数据库搜索 服务实现类
*
* @author xiongxiaoyang
* @date 2022/5/23
*/
@ConditionalOnProperty(prefix = "spring.elasticsearch", name = "enable", havingValue = "false")
@Service
@RequiredArgsConstructor
@Slf4j
public class DbSearchServiceImpl implements SearchService {
private final BookInfoMapper bookInfoMapper;
@Override
public RestResp<PageRespDto<BookInfoRespDto>> searchBooks(BookSearchReqDto condition) {
Page<BookInfoRespDto> page = new Page<>();
page.setCurrent(condition.getPageNum());
page.setSize(condition.getPageSize());
List<BookInfo> bookInfos = bookInfoMapper.searchBooks(page, condition);
return RestResp.ok(PageRespDto.of(condition.getPageNum(), condition.getPageSize(), page.getTotal()
, bookInfos.stream().map(v -> BookInfoRespDto.builder()
.id(v.getId())
.bookName(v.getBookName())
.categoryId(v.getCategoryId())
.categoryName(v.getCategoryName())
.authorId(v.getAuthorId())
.authorName(v.getAuthorName())
.wordCount(v.getWordCount())
.lastChapterName(v.getLastChapterName())
.build()).toList()));
}
}
- 新建
Elasticsearch 搜索引擎搜索服务实现类,实现从 Elasticsearch 中检索小说的业务逻辑,由配置项spring.elasticsearch.enable控制当 elasticsearch 开启时生效:
/**
* Elasticsearch 搜索 服务实现类
*
* @author xiongxiaoyang
* @date 2022/5/23
*/
@ConditionalOnProperty(prefix = "spring.elasticsearch", name = "enable", havingValue = "true")
@Service
@RequiredArgsConstructor
@Slf4j
public class EsSearchServiceImpl implements SearchService {
private final ElasticsearchClient esClient;
@SneakyThrows
@Override
public RestResp<PageRespDto<BookInfoRespDto>> searchBooks(BookSearchReqDto condition) {
SearchResponse<EsBookDto> response = esClient.search(s -> {
SearchRequest.Builder searchBuilder = s.index(EsConsts.IndexEnum.BOOK.getName());
buildSearchCondition(condition, searchBuilder);
// 排序
if (!StringUtils.isBlank(condition.getSort())) {
searchBuilder.sort(o ->
o.field(f -> f.field(StringUtils
.underlineToCamel(condition.getSort().split(" ")[0]))
.order(SortOrder.Desc))
);
}
// 分页
searchBuilder.from((condition.getPageNum() - 1) * condition.getPageSize())
.size(condition.getPageSize());
return searchBuilder;
},
EsBookDto.class
);
TotalHits total = response.hits().total();
List<BookInfoRespDto> list = new ArrayList<>();
List<Hit<EsBookDto>> hits = response.hits().hits();
for (Hit<EsBookDto> hit : hits) {
EsBookDto book = hit.source();
assert book != null;
list.add(BookInfoRespDto.builder()
.id(book.getId())
.bookName(book.getBookName())
.categoryId(book.getCategoryId())
.categoryName(book.getCategoryName())
.authorId(book.getAuthorId())
.authorName(book.getAuthorName())
.wordCount(book.getWordCount())
.lastChapterName(book.getLastChapterName())
.build());
}
assert total != null;
return RestResp.ok(PageRespDto.of(condition.getPageNum(), condition.getPageSize(), total.value(), list));
}
/**
* 构建查询条件
*/
private void buildSearchCondition(BookSearchReqDto condition, SearchRequest.Builder searchBuilder) {
BoolQuery boolQuery = BoolQuery.of(b -> {
if (!StringUtils.isBlank(condition.getKeyword())) {
// 关键词匹配
b.must((q -> q.multiMatch(t -> t
.fields("bookName^2","authorName^1.8","bookDesc^0.1")
.query(condition.getKeyword())
)
));
}
// 精确查询
if (Objects.nonNull(condition.getWorkDirection())) {
b.must(TermQuery.of(m -> m
.field("workDirection")
.value(condition.getWorkDirection())
)._toQuery());
}
if (Objects.nonNull(condition.getCategoryId())) {
b.must(TermQuery.of(m -> m
.field("categoryId")
.value(condition.getCategoryId())
)._toQuery());
}
// 范围查询
if (Objects.nonNull(condition.getWordCountMin())) {
b.must(RangeQuery.of(m -> m
.field("wordCount")
.gte(JsonData.of(condition.getWordCountMin()))
)._toQuery());
}
if (Objects.nonNull(condition.getWordCountMax())) {
b.must(RangeQuery.of(m -> m
.field("wordCount")
.lt(JsonData.of(condition.getWordCountMax()))
)._toQuery());
}
if (Objects.nonNull(condition.getUpdateTimeMin())) {
b.must(RangeQuery.of(m -> m
.field("lastChapterUpdateTime")
.gte(JsonData.of(condition.getUpdateTimeMin().getTime()))
)._toQuery());
}
return b;
});
searchBuilder.query(q -> q.bool(boolQuery));
}
}
BookController中注入SearchServicebean,调用searchBooks方法实现按配置动态切换搜索引擎的功能:
public class BookController {
private final SearchService searchService;
/**
* 小说搜索接口
*/
@GetMapping("search_list")
public RestResp<PageRespDto<BookInfoRespDto>> searchBooks(BookSearchReqDto condition) {
return searchService.searchBooks(condition);
}
}
# 使用 RabbitMQ 刷新 ES/Redis/Caffeine 等小说副本数据
在 novel 分布式环境中,数据库中的小说信息可能会在多个地方保存一份副本数据。例如,为了减轻数据库压力,提高并发和系统性能的本地缓存 Caffeine 和分布式缓存 Redis、为了实现小说全文高级检索的 Elasticsearch 搜索引擎等。有时为了应对小说详情页的高并发访问和 SEO 优化,我们还会选择为每一本小说生成静态化的页面,通过 Nginx 或 CDN 来访问。
此时,如果小说信息发生变更,那么如何通知所有的副本数据和静态页面更新呢?如果随着业务的发展和系统的演进,我们需要在 MongoDB 中增加一份存储副本,那么怎么在不修改调用方(所有小说信息发生变更的地方。例如,作家更新小说信息、作家发布新的章节或平台下架违规小说等场景)代码,不影响原先功能(其它副本数据的刷新)的同时,又能及时刷新 MongoDB 中的副本数据,实现模块间的解耦呢?
我们通过消息中间件来解决以上问题,实现步骤如下:
在
io.github.xxyopen.novel.core.constant包下创建 AMQP 相关常量类:
/**
* AMQP 相关常量
*
* @author xiongxiaoyang
* @date 2022/5/25
*/
public class AmqpConsts {
/**
* 小说信息改变 MQ
* */
public static class BookChangeMq{
/**
* 小说信息改变交换机
* */
public static final String EXCHANGE_NAME = "EXCHANGE-BOOK-CHANGE";
/**
* Elasticsearch book 索引更新的队列
* */
public static final String QUEUE_ES_UPDATE = "QUEUE-ES-BOOK-UPDATE";
/**
* Redis book 缓存更新的队列
* */
public static final String QUEUE_REDIS_UPDATE = "QUEUE-REDIS-BOOK-UPDATE";
// ... 其它的更新队列
}
}
- 在
io.github.xxyopen.novel.core.config包下创建 AMQP 配置类,配置各个交换机、队列以及绑定关系:
/**
* AMQP 配置类
*
* @author xiongxiaoyang
* @date 2022/5/25
*/
@Configuration
public class AmqpConfig {
/**
* 小说信息改变交换机
*/
@Bean
public FanoutExchange bookChangeExchange() {
return new FanoutExchange(AmqpConsts.BookChangeMq.EXCHANGE_NAME);
}
/**
* Elasticsearch book 索引更新队列
*/
@Bean
public Queue esBookUpdateQueue() {
return new Queue(AmqpConsts.BookChangeMq.QUEUE_ES_UPDATE);
}
/**
* Elasticsearch book 索引更新队列绑定到小说信息改变交换机
*/
@Bean
public Binding esBookUpdateQueueBinding() {
return BindingBuilder.bind(esBookUpdateQueue()).to(bookChangeExchange());
}
// ... 其它的更新队列以及绑定关系
}
- 在
io.github.xxyopen.novel.manager.mq包下创建 AMQP 消息管理类,用来发送各种 AMQP 消息:
/**
* AMQP 消息管理类
*
* @author xiongxiaoyang
* @date 2022/5/25
*/
@Component
@RequiredArgsConstructor
public class AmqpMsgManager {
private final AmqpTemplate amqpTemplate;
@Value("${spring.amqp.enable}")
private String enableAmqp;
/**
* 发送小说信息改变消息
*/
public void sendBookChangeMsg(Long bookId) {
if (Objects.equals(enableAmqp, CommonConsts.TRUE)) {
sendAmqpMessage(amqpTemplate, AmqpConsts.BookChangeMq.EXCHANGE_NAME, null, bookId);
}
}
private void sendAmqpMessage(AmqpTemplate amqpTemplate, String exchange, String routingKey, Object message) {
// 如果在事务中则在事务执行完成后再发送,否则可以直接发送
if (TransactionSynchronizationManager.isActualTransactionActive()) {
TransactionSynchronizationManager.registerSynchronization(new TransactionSynchronization() {
@Override
public void afterCommit() {
amqpTemplate.convertAndSend(exchange, routingKey, message);
}
});
return;
}
amqpTemplate.convertAndSend(exchange, routingKey, message);
}
}
- 在小说信息更新后,发送 AMQP 消息:
@Transactional(rollbackFor = Exception.class)
@Override
public RestResp<Void> saveBookChapter(ChapterAddReqDto dto) {
// 1) 保存章节相关信息到小说章节表
// a) 查询最新章节号
int chapterNum = 0;
QueryWrapper<BookChapter> chapterQueryWrapper = new QueryWrapper<>();
chapterQueryWrapper.eq(DatabaseConsts.BookChapterTable.COLUMN_BOOK_ID,dto.getBookId())
.orderByDesc(DatabaseConsts.BookChapterTable.COLUMN_CHAPTER_NUM)
.last(DatabaseConsts.SqlEnum.LIMIT_1.getSql());
BookChapter bookChapter = bookChapterMapper.selectOne(chapterQueryWrapper);
if(Objects.nonNull(bookChapter)){
chapterNum = bookChapter.getChapterNum() + 1;
}
// b) 设置章节相关信息并保存
BookChapter newBookChapter = new BookChapter();
newBookChapter.setBookId(dto.getBookId());
newBookChapter.setChapterName(dto.getChapterName());
newBookChapter.setChapterNum(chapterNum);
newBookChapter.setWordCount(dto.getChapterContent().length());
newBookChapter.setIsVip(dto.getIsVip());
newBookChapter.setCreateTime(LocalDateTime.now());
newBookChapter.setUpdateTime(LocalDateTime.now());
bookChapterMapper.insert(newBookChapter);
// 2) 保存章节内容到小说内容表
BookContent bookContent = new BookContent();
bookContent.setContent(dto.getChapterContent());
bookContent.setChapterId(newBookChapter.getId());
bookContent.setCreateTime(LocalDateTime.now());
bookContent.setUpdateTime(LocalDateTime.now());
bookContentMapper.insert(bookContent);
// 3) 更新小说表最新章节信息和小说总字数信息
// a) 更新小说表关于最新章节的信息
BookInfoRespDto bookInfo = bookInfoCacheManager.getBookInfo(dto.getBookId());
BookInfo newBookInfo = new BookInfo();
newBookInfo.setId(dto.getBookId());
newBookInfo.setLastChapterId(newBookChapter.getId());
newBookInfo.setLastChapterName(newBookChapter.getChapterName());
newBookInfo.setLastChapterUpdateTime(LocalDateTime.now());
newBookInfo.setWordCount(bookInfo.getWordCount() + newBookChapter.getWordCount());
newBookChapter.setUpdateTime(LocalDateTime.now());
bookInfoMapper.updateById(newBookInfo);
// b) 刷新小说信息缓存
bookInfoCacheManager.cachePutBookInfo(dto.getBookId());
// c) 发送小说信息更新的 MQ 消息
amqpMsgManager.sendBookChangeMsg(dto.getBookId());
return RestResp.ok();
}
- 在
io.github.xxyopen.novel.core.listener包下创建 Rabbit 队列监听器,监听各个 RabbitMQ 队列的消息并处理:
/**
* Rabbit 队列监听器
*
* @author xiongxiaoyang
* @date 2022/5/25
*/
@Component
@RequiredArgsConstructor
@Slf4j
public class RabbitQueueListener {
private final BookInfoMapper bookInfoMapper;
private final ElasticsearchClient esClient;
/**
* 监听小说信息改变的 ES 更新队列,更新最新小说信息到 ES
* */
@RabbitListener(queues = AmqpConsts.BookChangeMq.QUEUE_ES_UPDATE)
@SneakyThrows
public void updateEsBook(Long bookId) {
BookInfo bookInfo = bookInfoMapper.selectById(bookId);
IndexResponse response = esClient.index(i -> i
.index(EsConsts.BookIndex.INDEX_NAME)
.id(bookInfo.getId().toString())
.document(EsBookDto.build(bookInfo))
);
log.info("Indexed with version " + response.version());
}
// ... 监听其它队列,刷新其它副本数据
}
此时,如果需要更新其它副本数据,只需要配置更新队列和增加监听器,不需要修改任何业务代码,而且任意副本的数据刷新互不影响,真正实现了模块间的解耦。
注:当服务集群部署时,由于多个消费者绑定同一个队列是无法同时消费的,一个消息只能被一个消费者消费,所以刷新本地缓存的 MQ 队列命名应该使用固定名 + 唯一随机值这种动态形式。这样每次启动会生成一个新的队列,我们需要设置该队列的 autoDelete = true,让所有消费客户端连接断开时自动删除该队列。
# 使用 XXL-JOB 优化 Elasticsearch 数据同步任务
登录调度中心后台,新增 novel 项目任务执行器:
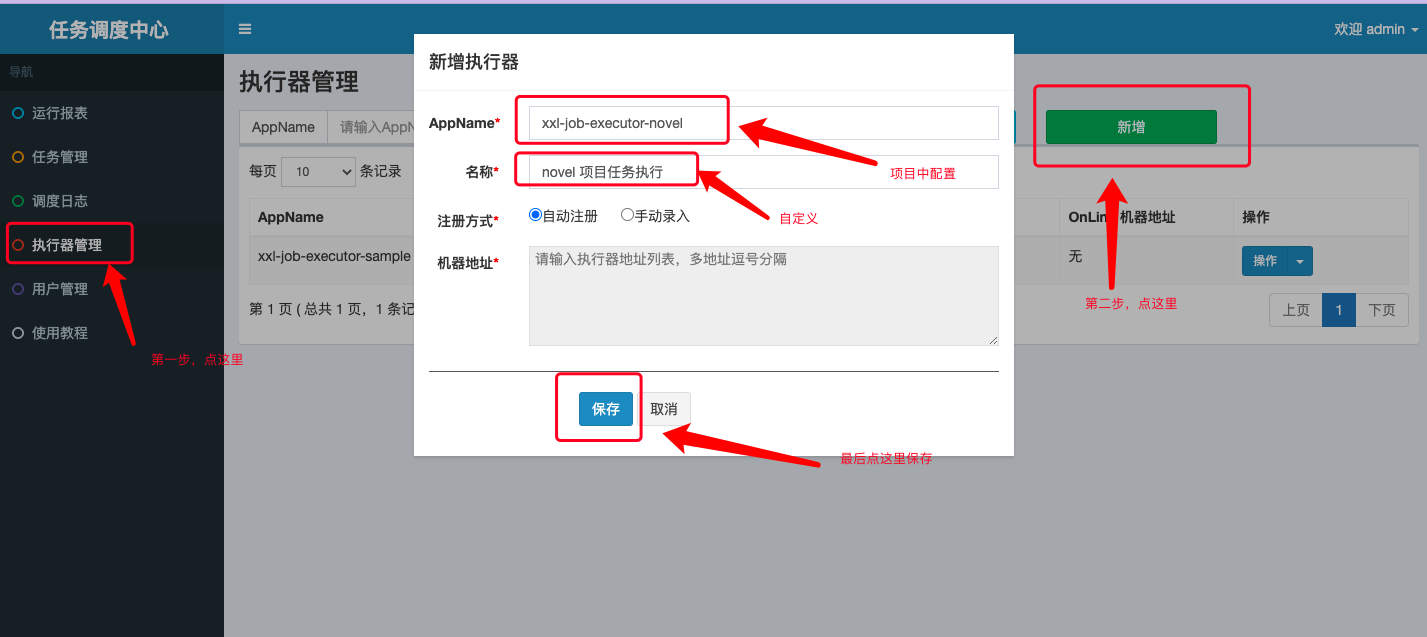
注:AppName 的值需要和 novel 项目 application.yml 配置文件中配置的值保持一致。
- 新增 Elasticsearch 数据同步任务:
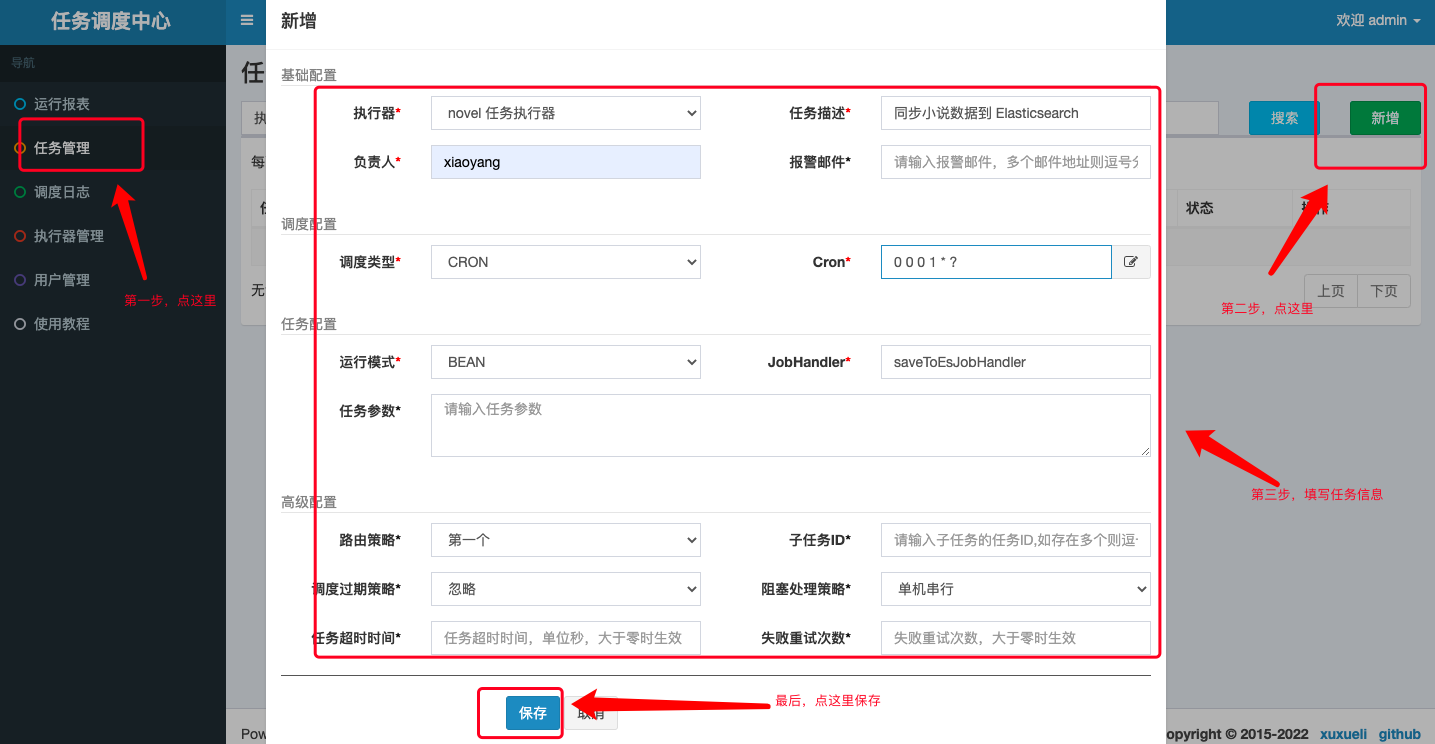
- 修改
io.github.xxyopen.novel.core.task包下的 Elasticsearch 数据同步任务(@Scheduled注解 替换为@XxlJob 注解):
/**
* 小说数据同步到 Elasticsearch 任务
*
* @author xiongxiaoyang
* @date 2022/5/23
*/
@ConditionalOnProperty(prefix = "spring.elasticsearch", name = "enable", havingValue = "true")
@Component
@RequiredArgsConstructor
@Slf4j
public class BookToEsTask {
private final BookInfoMapper bookInfoMapper;
private final ElasticsearchClient elasticsearchClient;
@SneakyThrows
@XxlJob("saveToEsJobHandler") // 此处需要和调度中心创建任务时填写的 JobHandler 值保持一致
public ReturnT<String> saveToEs() {
try {
QueryWrapper<BookInfo> queryWrapper = new QueryWrapper<>();
List<BookInfo> bookInfos;
long maxId = 0;
for (; ; ) {
queryWrapper.clear();
queryWrapper
.orderByAsc(DatabaseConsts.CommonColumnEnum.ID.getName())
.gt(DatabaseConsts.CommonColumnEnum.ID.getName(), maxId)
.last(DatabaseConsts.SqlEnum.LIMIT_30.getSql());
bookInfos = bookInfoMapper.selectList(queryWrapper);
if (bookInfos.isEmpty()) {
break;
}
BulkRequest.Builder br = new BulkRequest.Builder();
for (BookInfo book : bookInfos) {
br.operations(op -> op
.index(idx -> idx
.index(EsConsts.BookIndex.INDEX_NAME)
.id(book.getId().toString())
.document(EsBookDto.build(book))
)
).timeout(Time.of(t -> t.time("10s")));
maxId = book.getId();
}
BulkResponse result = elasticsearchClient.bulk(br.build());
// Log errors, if any
if (result.errors()) {
log.error("Bulk had errors");
for (BulkResponseItem item : result.items()) {
if (item.error() != null) {
log.error(item.error().reason());
}
}
}
}
return ReturnT.SUCCESS;
} catch (Exception e) {
log.error(e.getMessage(), e);
return ReturnT.FAIL;
}
}
}
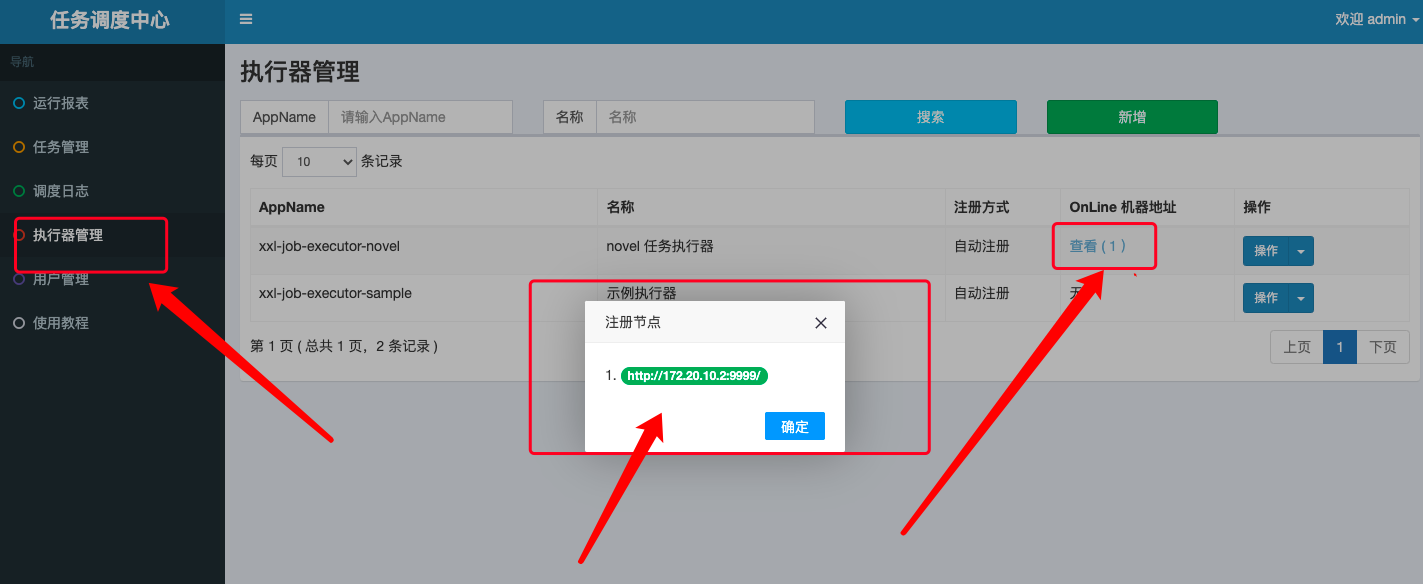
- 查看任务执行器,可以发现已经有一台机器自动注册:
- 进入任务管理,我们可以启动 Elasticsearch 数据同步任务,由配置的 Cron 表达式进行任务调度;也可以选择手动触发一次任务执行:
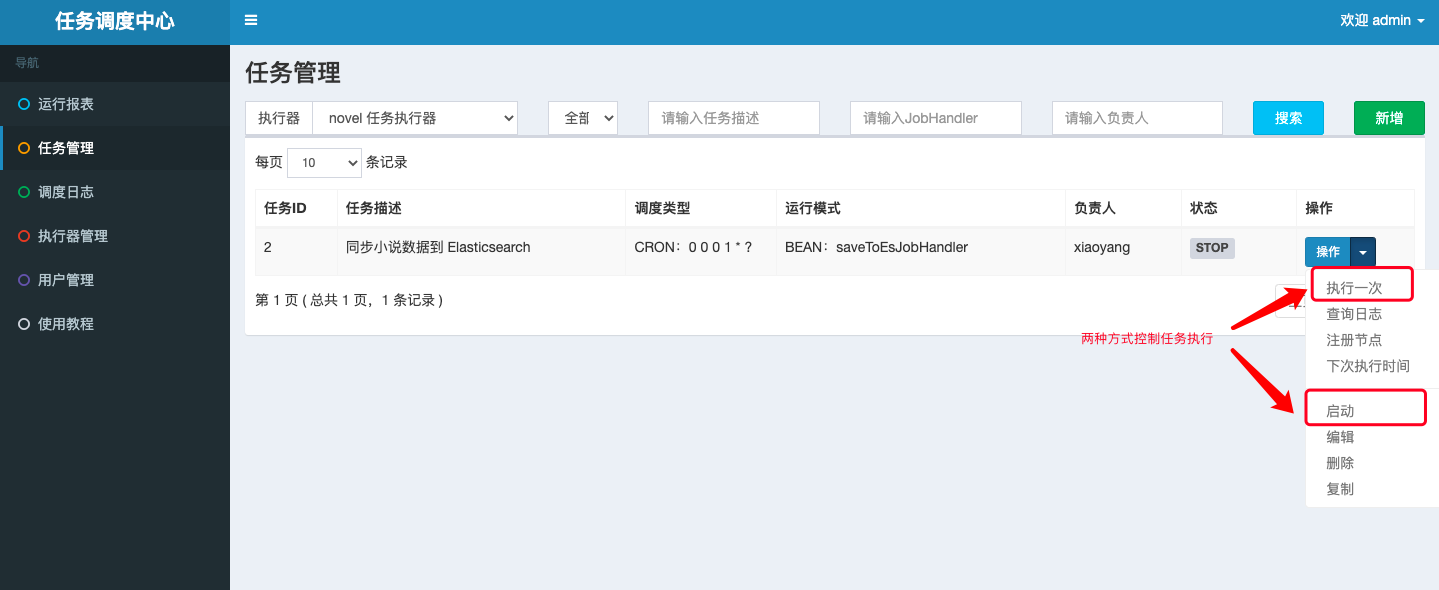
此时,我们可以在任意时刻手动同步数据库的小说数据到 Elasticsearch 搜索引擎中,极大的方便了我们的开发测试工作。
# 使用 Sentinel 实现接口防刷和限流
# 问题
novel 作为一个互联网系统,经常会遇到非法爬虫(例如,盗版小说网站)来爬取我们系统的小说数据,这种爬虫行为有时会高达每秒几百甚至上千次访问。防刷的目的是为了限制这些爬虫请求我们接口的频率,如果我们不做接口防刷限制的话,我们系统很容易就会被爬虫干倒。
限流的目的是在流量高峰期间,根据我们系统的承受能力,限制同时请求的数量,保证多余的请求会阻塞一段时间再处理,不简单粗暴的直接返回错误信息让客户端重试,同时又能起到流量削峰的作用。
很多时候,我们都是尽量将请求拦截在系统上游,比如在反向代理层通过 Nginx + Lua + Redis 来实现限流功能,这个在后面部署篇章里面会详细地讲解如何实现。如果我们系统还没有使用类似于 Nginx 一样的反向代理,又或者我们想实现更复杂的流量控制,想要一个人性化的控制面板来动态限流和实时监控,那么我们可以使用阿里巴巴开源的高可用流控防护组件 Sentinel 来实现。
# Sentinel 介绍
Sentinel 是一个面向云原生微服务的高可用流控防护组件,以流量为切入点,从流量控制、熔断降级、系统负载保护等多个维度保护服务的稳定性。
Sentinel 有两个重要的概念,资源和规则:
资源是 Sentinel 的关键概念。它可以是 Java 应用程序中的任何内容,例如,由应用程序提供的服务,或由应用程序调用的其它应用提供的服务,甚至可以是一段代码。只要通过 Sentinel API 定义的代码,就是资源,能够被 Sentinel 保护起来。大部分情况下,可以使用方法签名,URL,甚至服务名称作为资源名来标示资源。
规则是围绕资源的实时状态设定的规则,可以包括流量控制规则、熔断降级规则以及系统保护规则。所有规则可以动态实时调整。
Sentinel 具有以下特征:
丰富的应用场景:Sentinel 承接了阿里巴巴近 10 年的双十一大促流量的核心场景,例如秒杀(即突发流量控制在系统容量可以承受的范围)、消息削峰填谷、集群流量控制、实时熔断下游不可用应用等。
完备的实时监控:Sentinel 同时提供实时的监控功能。您可以在控制台中看到接入应用的单台机器秒级数据,甚至 500 台以下规模的集群的汇总运行情况。
广泛的开源生态:Sentinel 提供开箱即用的与其它开源框架/库的整合模块,例如与 Spring Cloud、Apache Dubbo、gRPC、Quarkus 的整合。您只需要引入相应的依赖并进行简单的配置即可快速地接入 Sentinel。同时 Sentinel 提供 Java/Go/C++ 等多语言的原生实现。
完善的 SPI 扩展机制:Sentinel 提供简单易用、完善的 SPI 扩展接口。您可以通过实现扩展接口来快速地定制逻辑。例如定制规则管理、适配动态数据源等。
Sentinel 分为核心库和控制台两部分,核心库不依赖控制台,但是结合控制台可以取得最好的效果:
核心库(Java 客户端)不依赖任何框架/库,能够运行于所有 Java 运行时环境,同时对 Dubbo / Spring Cloud 等框架也有较好的支持。
控制台(Dashboard)基于 Spring Boot 开发,打包后可以直接运行,不需要额外的 Tomcat 等应用容器。
# 使用 Sentinel 核心库实现接口防刷和限流
- 引入 Sentinel 相关依赖:
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-core</artifactId>
<version>${sentinel.version}</version>
</dependency>
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-parameter-flow-control</artifactId>
<version>${sentinel.version}</version>
</dependency>
- 在
io.github.xxyopen.novel.core.config.WebConfig中注册一个全局的拦截器拦截所有的请求:
// 流量限制拦截器
registry.addInterceptor(flowLimitInterceptor)
.addPathPatterns("/**")
.order(0);
- 拦截器中定义资源和规则,资源在
preHandle方法中定义,为所有请求的入口,接口限流规则和接口防刷规则通过static 代码块在类加载时初始化:
/**
* 流量限制 拦截器
* 实现接口防刷和限流
*
* @author xiongxiaoyang
* @date 2022/6/1
*/
@Component
@RequiredArgsConstructor
@Slf4j
public class FlowLimitInterceptor implements HandlerInterceptor {
private final ObjectMapper objectMapper;
/**
* novel 项目所有的资源
*/
private static final String NOVEL_RESOURCE = "novelResource";
static {
// 接口限流规则:所有的请求,限制每秒最多只能通过 2000 个,超出限制匀速排队
List<FlowRule> rules = new ArrayList<>();
FlowRule rule1 = new FlowRule();
rule1.setResource(NOVEL_RESOURCE);
rule1.setGrade(RuleConstant.FLOW_GRADE_QPS);
// Set limit QPS to 2000.
rule1.setCount(2000);
rule1.setControlBehavior(RuleConstant.CONTROL_BEHAVIOR_RATE_LIMITER);
rules.add(rule1);
FlowRuleManager.loadRules(rules);
// 接口防刷规则 1:所有的请求,限制每个 IP 每秒最多只能通过 50 个,超出限制直接拒绝
ParamFlowRule rule2 = new ParamFlowRule(NOVEL_RESOURCE)
.setParamIdx(0)
.setCount(50);
// 接口防刷规则 2:所有的请求,限制每个 IP 每分钟最多只能通过 1000 个,超出限制直接拒绝
ParamFlowRule rule3 = new ParamFlowRule(NOVEL_RESOURCE)
.setParamIdx(0)
.setCount(1000)
.setDurationInSec(60);
ParamFlowRuleManager.loadRules(Arrays.asList(rule2, rule3));
}
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
String ip = IpUtils.getRealIp(request);
Entry entry = null;
try {
// 若需要配置例外项,则传入的参数只支持基本类型。
// EntryType 代表流量类型,其中系统规则只对 IN 类型的埋点生效
// count 大多数情况都填 1,代表统计为一次调用。
entry = SphU.entry(NOVEL_RESOURCE, EntryType.IN, 1, ip);
// Your logic here.
return HandlerInterceptor.super.preHandle(request, response, handler);
} catch (BlockException ex) {
// Handle request rejection.
log.info("IP:{}被限流了!", ip);
response.setCharacterEncoding(StandardCharsets.UTF_8.name());
response.setContentType(MediaType.APPLICATION_JSON_VALUE);
response.getWriter().write(objectMapper.writeValueAsString(RestResp.fail(ErrorCodeEnum.USER_REQ_MANY)));
} finally {
// 注意:exit 的时候也一定要带上对应的参数,否则可能会有统计错误。
if (entry != null) {
entry.exit(1, ip);
}
}
return false;
}
}
规则属性说明:
| 属性 | 说明 | 默认值 |
|---|---|---|
| resource | 资源名,必填 | |
| count | 限流阈值,必填 | |
| grade | 限流模式 | QPS 模式 |
| durationInSec | 统计窗口时间长度(单位为秒),1.6.0 版本开始支持 | 1s |
| controlBehavior | 流控效果(支持快速失败和匀速排队模式),1.6.0 版本开始支持 | 快速失败 |
| maxQueueingTimeMs | 最大排队等待时长(仅在匀速排队模式生效),1.6.0 版本开始支持 | 0ms |
| paramIdx | 热点参数的索引,必填,对应 SphU.entry(xxx, args) 中的参数索引位置 | |
| paramFlowItemList | 参数例外项,可以针对指定的参数值单独设置限流阈值,不受前面 count 阈值的限制。仅支持基本类型和字符串类型 | |
| clusterMode | 是否是集群参数流控规则 | false |
| clusterConfig | 集群流控相关配置 |
我们还可以通过 Sentinel 提供的注解支持模块来定义我们的资源,如下所示,helloWorld() 方法成了我们的一个资源:
@SentinelResource("HelloWorld")
public void helloWorld() {
// 资源中的逻辑
System.out.println("hello world");
}
注:注解支持模块需要配合 Spring AOP 或者 AspectJ 一起使用。
此时,我们已经实现了接口防刷和限流的功能,如果我们需要实时监控和管理限流规则,那么我们可以按如下步骤接入 Sentinel 开源控制台:
下载控制台 jar 包并在本地启动
novel 项目引入 Transport 模块来与 Sentinel 控制台进行通信
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-transport-simple-http</artifactId>
<version>1.8.4</version>
</dependency>
- novel 项目启动时加入 JVM 参数 -Dcsp.sentinel.dashboard.server=consoleIp:port 指定控制台地址和端口
- 确保 novel 项目有访问量
完成以上步骤后即可在 Sentinel 控制台上看到对应的应用,机器列表页面可以看到对应的机器。
# 集成 ShardingSphere-JDBC 优化小说内容存储
# 背景
传统的将数据集中存储至单一节点的解决方案,在性能、可用性和运维成本这三方面已经难于满足海量数据的场景。
从性能方面来说,由于关系型数据库大多采用 B+ 树类型的索引,在数据量超过阈值的情况下,索引深度的增加也将使得磁盘访问的 IO 次数增加,进而导致查询性能的下降; 同时,高并发访问请求也使得集中式数据库成为系统的最大瓶颈。
从可用性的方面来讲,服务化的无状态性,能够达到较小成本的随意扩容,这必然导致系统的最终压力都落在数据库之上。 而单一的数据节点,或者简单的主从架构,已经越来越难以承担。数据库的可用性,已成为整个系统的关键。
从运维成本方面考虑,当一个数据库实例中的数据达到阈值以上,对于 DBA 的运维压力就会增大。 数据备份和恢复的时间成本都将随着数据量的大小而愈发不可控。一般来讲,单一数据库实例的数据的阈值在 1TB 之内,是比较合理的范围。
数据分片指按照某个维度将存放在单一数据库中的数据分散地存放至多个数据库或表中以达到提升性能瓶颈以及可用性的效果。通过分库和分表进行数据的拆分来使得各个表的数据量保持在阈值以下,以及对流量进行疏导应对高访问量,是应对高并发和海量数据系统的有效手段。分库和分表均可以有效的避免由数据量超过可承受阈值而产生的查询瓶颈。
小说数据有着内容多、增长速度快的特点,一本主流的完结小说一般所需存储空间大概在 5MB 以上。一个主流的小说网站在发展中后期,数据量是远远超过单一数据库实例的阈值的,所以我们对小说内容进行分库分表存储是非常有必要的。在发展初期,我们的数据量还不是很大,可以先将小说内容分表存储以减轻数据库单表压力以及为后期的数据库分库做准备。等数据量即将超过阈值时,再迁移到不同的数据库实例上。
注:数据分片分为按照业务将表进行归类,分布到不同的数据库中的垂直分片和通过某个字段(或某几个字段)按照某种规则将数据分散至多个库或表中的水平分片。
# Apache ShardingSphere 介绍
Apache ShardingSphere 产品定位为 Database Plus,它关注如何充分合理地利用数据库的计算和存储能力,而并非实现一个全新的数据库。ShardingSphere 站在数据库的上层视角,关注他们之间的协作多于数据库自身,由 JDBC、Proxy 和 Sidecar(规划中)这 3 款既能够独立部署,又支持混合部署配合使用的产品组成。 它们均提供标准化的基于数据库作为存储节点的增量功能,可适用于如 Java 同构、异构语言、云原生等各种多样化的应用场景。
ShardingSphere-JDBC 定位为轻量级 Java 框架,在 Java 的 JDBC 层提供额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
ShardingSphere-Proxy 定位为透明化的数据库代理端,提供封装了数据库二进制协议的服务端版本,用于完成对异构语言的支持。
ShardingSphere-Sidecar 定位为 Kubernetes 的云原生数据库代理,以 Sidecar 的形式代理所有对数据库的访问。 通过无中心、零侵入的方案提供与数据库交互的啮合层,即 Database Mesh,又可称数据库网格。
连接、增量 和 可插拔 是 Apache ShardingSphere 的核心概念:
连接:通过对数据库协议、SQL 方言以及数据库存储的灵活适配,快速的连接应用与多模式的异构数据库;
增量:获取数据库的访问流量,并提供流量重定向(数据分片、读写分离、影子库)、流量变形(数据加密、数据脱敏)、流量鉴权(安全、审计、权限)、流量治理(熔断、限流)以及流量分析(服务质量分析、可观察性)等透明化增量功能;
可插拔:项目采用微内核 + 三层可插拔模型,使内核、功能组件以及生态对接完全能够灵活的方式进行插拔式扩展,开发者能够像使用积木一样定制属于自己的独特系统。
Apache ShardingSphere 的数据分片模块透明化了分库分表所带来的影响,让使用方尽量像使用一个数据库一样使用水平分片之后的数据库集群。
# 集成步骤
- MySQL 执行以下的数据迁移脚本:
DROP PROCEDURE
IF
EXISTS createBookChapterTable;
-- 创建小说章节表的存储过程
CREATE PROCEDURE createBookChapterTable ( ) BEGIN
-- 定义变量
DECLARE
i INT DEFAULT 0;
DECLARE
tableName CHAR ( 13 ) DEFAULT NULL;
WHILE
i < 10 DO
SET tableName = concat( 'book_chapter', i );
SET @stmt = concat( 'create table ', tableName, '(
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`book_id` bigint(20) unsigned NOT NULL COMMENT \'小说ID\',
`chapter_num` smallint(5) unsigned NOT NULL COMMENT \'章节号\',
`chapter_name` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT \'章节名\',
`word_count` int(10) unsigned NOT NULL COMMENT \'章节字数\',
`is_vip` tinyint(3) unsigned NOT NULL DEFAULT \'0\' COMMENT \'是否收费;1-收费 0-免费\',
`create_time` datetime DEFAULT NULL,
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
UNIQUE KEY `uk_bookId_chapterNum` (`book_id`,`chapter_num`) USING BTREE,
UNIQUE KEY `pk_id` (`id`) USING BTREE,
KEY `idx_bookId` (`book_id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT=\'小说章节\'' );
PREPARE stmt
FROM
@stmt;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
SET i = i + 1;
END WHILE;
END;
CALL createBookChapterTable ( );
DROP PROCEDURE
IF
EXISTS createBookContentTable;
-- 创建小说内容表的存储过程
CREATE PROCEDURE createBookContentTable ( ) BEGIN
-- 定义变量
DECLARE
i INT DEFAULT 0;
DECLARE
tableName CHAR ( 13 ) DEFAULT NULL;
WHILE
i < 10 DO
SET tableName = concat( 'book_content', i );
SET @stmt = concat( 'create table ', tableName, '(
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT \'主键\',
`chapter_id` bigint(20) unsigned NOT NULL COMMENT \'章节ID\',
`content` mediumtext CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT \'小说章节内容\',
`create_time` datetime DEFAULT NULL,
`update_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
UNIQUE KEY `uk_chapterId` (`chapter_id`) USING BTREE,
UNIQUE KEY `pk_id` (`id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT=\'小说内容\'' );
PREPARE stmt
FROM
@stmt;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
SET i = i + 1;
END WHILE;
END;
CALL createBookContentTable ( );
DROP PROCEDURE
IF
EXISTS copyBookChapterData;
-- 迁移小说章节数据的存储过程
CREATE PROCEDURE copyBookChapterData ( ) BEGIN
-- 定义变量
DECLARE
s INT DEFAULT 0;
DECLARE
chapterId BIGINT;
DECLARE
bookId BIGINT;
DECLARE
chapterNum SMALLINT;
DECLARE
chapterName VARCHAR ( 100 );
DECLARE
wordCount INT DEFAULT 0;
DECLARE
isVip TINYINT ( 64 ) DEFAULT 0;
DECLARE
createTime datetime DEFAULT NULL;
DECLARE
updateTime datetime DEFAULT NULL;
DECLARE
tableNumber INT DEFAULT 0;
DECLARE
tableName CHAR ( 13 ) DEFAULT NULL;
-- 定义游标
DECLARE
report CURSOR FOR SELECT
id,
book_id,
chapter_num,
chapter_name,
word_count,
is_vip,
create_time,
update_time
FROM
book_chapter;
-- 声明当游标遍历完后将标志变量置成某个值
DECLARE
CONTINUE HANDLER FOR NOT FOUND
SET s = 1;
-- 打开游标
OPEN report;
-- 将游标中的值赋值给变量,注意:变量名不要和返回的列名同名,变量顺序要和sql结果列的顺序一致
FETCH report INTO chapterId,
bookId,
chapterNum,
chapterName,
wordCount,
isVip,
createTime,
updateTime;
-- 循环遍历
WHILE
s <> 1 DO
-- 执行业务逻辑
SET tableNumber = bookId % 10;
SET tableName = concat( 'book_chapter', tableNumber );
SET @stmt = concat(
'insert into ',
tableName,
'(`id`, `book_id`, `chapter_num`, `chapter_name`, `word_count`, `is_vip`, `create_time`, `update_time`) VALUES (',
chapterId,
', ',
bookId,
', ',
chapterNum,
', \'',
chapterName,
'\', ',
wordCount,
', ',
isVip,
', \'',
createTime,
'\', \'',
updateTime,
'\')'
);
PREPARE stmt
FROM
@stmt;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
FETCH report INTO chapterId,
bookId,
chapterNum,
chapterName,
wordCount,
isVip,
createTime,
updateTime;
END WHILE;
-- 关闭游标
CLOSE report;
END;
CALL copyBookChapterData ( );
DROP PROCEDURE
IF
EXISTS copyBookContentData;
-- 迁移小说内容数据的存储过程
CREATE PROCEDURE copyBookContentData ( ) BEGIN
-- 定义变量
DECLARE
s INT DEFAULT 0;
DECLARE
contentId BIGINT;
DECLARE
chapterId BIGINT;
DECLARE
bookContent MEDIUMTEXT;
DECLARE
createTime datetime DEFAULT NULL;
DECLARE
updateTime datetime DEFAULT NULL;
DECLARE
tableNumber INT DEFAULT 0;
DECLARE
tableName CHAR ( 13 ) DEFAULT NULL;
-- 定义游标
DECLARE
report CURSOR FOR SELECT
id,
chapter_id,
content,
create_time,
update_time
FROM
book_content;
-- 声明当游标遍历完后将标志变量置成某个值
DECLARE
CONTINUE HANDLER FOR NOT FOUND
SET s = 1;
-- 打开游标
OPEN report;
-- 将游标中的值赋值给变量,注意:变量名不要和返回的列名同名,变量顺序要和sql结果列的顺序一致
FETCH report INTO contentId,
chapterId,
bookContent,
createTime,
updateTime;
-- 循环遍历
WHILE
s <> 1 DO
-- 执行业务逻辑
SET tableNumber = chapterId % 10;
SET tableName = concat( 'book_content', tableNumber );
SET bookContent = REPLACE ( bookContent, '\'', "\\'" );
SET @stmt = concat(
'insert into ',
tableName,
'(`id`, `chapter_id`, `content`) VALUES (',
contentId,
', ',
chapterId,
',\'',
bookContent,
'\')'
);
PREPARE stmt
FROM
@stmt;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
FETCH report INTO contentId,
chapterId,
bookContent,
createTime,
updateTime;
END WHILE;
-- 关闭游标
CLOSE report;
END;
CALL copyBookContentData ( );
- 引入 ShardingSphere-JDBC 官方提供的 Spring Boot Starter 依赖:
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
<version>5.1.1</version>
</dependency>
- application.yml 中添加 ShardingSphere-JDBC 的配置:
spring:
shardingsphere:
# 是否开启 shardingsphere
enabled: false
props:
# 是否在日志中打印 SQL
sql-show: true
# 模式配置
mode:
# 单机模式
type: Standalone
repository:
# 文件持久化
type: File
props:
# 元数据存储路径
path: .shardingsphere
# 使用本地配置覆盖持久化配置
overwrite: true
# 数据源配置
datasource:
names: ds_0
ds_0:
type: com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.cj.jdbc.Driver
jdbcUrl: jdbc:mysql://localhost:3306/novel_test?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai
username: root
password: test123456
# 规则配置
rules:
# 数据分片
sharding:
tables:
# book_content 表
book_content:
# 数据节点
actual-data-nodes: ds_$->{0}.book_content$->{0..9}
# 分表策略
table-strategy:
standard:
# 分片列名称
sharding-column: chapter_id
# 分片算法名称
sharding-algorithm-name: bookContentSharding
sharding-algorithms:
bookContentSharding:
# 行表达式分片算法,使用 Groovy 的表达式,提供对 SQL 语句中的 = 和 IN 的分片操作支持
type: INLINE
props:
# 分片算法的行表达式
algorithm-expression: book_content$->{chapter_id % 10}
配置是 ShardingSphere-JDBC 中唯一与应用开发者交互的模块,通过它可以快速清晰的理解 ShardingSphere-JDBC 所提供的功能。
模式配置: Apache ShardingSphere 提供的 3 种运行模式分别是适用于集成测试的环境启动,方便开发人员在整合功能测试中集成 Apache ShardingSphere 而无需清理运行痕迹
内存模式、能够将数据源和规则等元数据信息持久化,但无法将元数据同步至多个 Apache ShardingSphere 实例,无法在集群环境中相互感知的单机模式和提供了多个 Apache ShardingSphere 实例之间的元数据共享和分布式场景下状态协调能力的集群模式。数据源配置:包括使用本地数据源配置(本项目中)和使用 JNDI 数据源的配置。如果计划使用 JNDI 配置数据库,在应用容器(如 Tomcat)中使用 ShardingSphere-JDBC 时, 可使用 spring.shardingsphere.datasource.${datasourceName}.jndiName 来代替数据源的一系列配置。
规则配置:规则是 Apache ShardingSphere 面向可插拔的一部分,包括数据分片、读写分离、高可用、数据加密、影子库、SQL 解析、混合规则等。
以下是数据分片的配置项说明:
# 标准分片表配置
spring.shardingsphere.rules.sharding.tables.<table-name>.actual-data-nodes= # 由数据源名 + 表名组成,以小数点分隔。多个表以逗号分隔,支持 inline 表达式。缺省表示使用已知数据源与逻辑表名称生成数据节点,用于广播表(即每个库中都需要一个同样的表用于关联查询,多为字典表)或只分库不分表且所有库的表结构完全一致的情况
# 分库策略,缺省表示使用默认分库策略,以下的分片策略只能选其一
# 用于单分片键的标准分片场景
spring.shardingsphere.rules.sharding.tables.<table-name>.database-strategy.standard.sharding-column= # 分片列名称
spring.shardingsphere.rules.sharding.tables.<table-name>.database-strategy.standard.sharding-algorithm-name= # 分片算法名称
# 用于多分片键的复合分片场景
spring.shardingsphere.rules.sharding.tables.<table-name>.database-strategy.complex.sharding-columns= # 分片列名称,多个列以逗号分隔
spring.shardingsphere.rules.sharding.tables.<table-name>.database-strategy.complex.sharding-algorithm-name= # 分片算法名称
# 用于 Hint 的分片策略
spring.shardingsphere.rules.sharding.tables.<table-name>.database-strategy.hint.sharding-algorithm-name= # 分片算法名称
# 分表策略,同分库策略
spring.shardingsphere.rules.sharding.tables.<table-name>.table-strategy.xxx= # 省略
# 自动分片表配置
spring.shardingsphere.rules.sharding.auto-tables.<auto-table-name>.actual-data-sources= # 数据源名
spring.shardingsphere.rules.sharding.auto-tables.<auto-table-name>.sharding-strategy.standard.sharding-column= # 分片列名称
spring.shardingsphere.rules.sharding.auto-tables.<auto-table-name>.sharding-strategy.standard.sharding-algorithm-name= # 自动分片算法名称
# 分布式序列策略配置
spring.shardingsphere.rules.sharding.tables.<table-name>.key-generate-strategy.column= # 分布式序列列名称
spring.shardingsphere.rules.sharding.tables.<table-name>.key-generate-strategy.key-generator-name= # 分布式序列算法名称
spring.shardingsphere.rules.sharding.binding-tables[0]= # 绑定表规则列表
spring.shardingsphere.rules.sharding.binding-tables[1]= # 绑定表规则列表
spring.shardingsphere.rules.sharding.binding-tables[x]= # 绑定表规则列表
spring.shardingsphere.rules.sharding.broadcast-tables[0]= # 广播表规则列表
spring.shardingsphere.rules.sharding.broadcast-tables[1]= # 广播表规则列表
spring.shardingsphere.rules.sharding.broadcast-tables[x]= # 广播表规则列表
spring.shardingsphere.sharding.default-database-strategy.xxx= # 默认数据库分片策略
spring.shardingsphere.sharding.default-table-strategy.xxx= # 默认表分片策略
spring.shardingsphere.sharding.default-key-generate-strategy.xxx= # 默认分布式序列策略
spring.shardingsphere.sharding.default-sharding-column= # 默认分片列名称
# 分片算法配置
spring.shardingsphere.rules.sharding.sharding-algorithms.<sharding-algorithm-name>.type= # 分片算法类型
spring.shardingsphere.rules.sharding.sharding-algorithms.<sharding-algorithm-name>.props.xxx= # 分片算法属性配置
# 分布式序列算法配置
spring.shardingsphere.rules.sharding.key-generators.<key-generate-algorithm-name>.type= # 分布式序列算法类型
spring.shardingsphere.rules.sharding.key-generators.<key-generate-algorithm-name>.props.xxx= # 分布式序列算法属性配置
其中,分片算法分为包含取模分片、哈希取模分片、基于分片容量的范围分片、基于分片边界的范围分片、自动时间段分片在内的自动分片算法和包含行表达式分片、时间范围分片在内的标准分片算法以及复合分片算法和Hint 分片算法。我们还可以自定义类分片算法,通过配置分片策略类型和算法类名,实现自定义扩展。
分布式序列算法包括雪花算法和 UUID。
# 集成 Spring Boot Admin 实现应用管理和监控功能
# Spring Boot Actuator 介绍
当我们将应用程序投入生产时,Spring Boot 包含了许多可以帮助我们对其进行监控和管理的生产就绪功能,我们可以选择使用 HTTP 端点或 JMX 来管理和监控我们的应用程序。
Spring Boot Actuator 模块提供了 Spring Boot 的所有生产就绪功能,我们通过添加 spring-boot-starter-actuator Starter依赖来启用这些功能。
端点(endpoints)让我们可以监控应用程序并与之交互。Spring Boot 包含许多内置端点,并允许我们添加自己的端点。例如,health 端点提供基本的应用程序健康信息。我们可以单独启用或禁用每一个端点并通过 HTTP 或 JMX 公开它们(使它们可以远程访问)。当端点被启用和公开时,它被认为是可用的,内置端点仅在可用时才会自动配置。
大多数应用程序选择通过 HTTP 公开端点,其中端点的 ID 和前缀 /actuator 被映射到一个 URL 地址。例如,默认情况下,health 端点映射到 /actuator/health。
默认情况下,除了 shutdown 之外的所有端点都是启用的,如果要配置一个端点的启用,需要使用 management.endpoint.<id>.enabled 配置属性。
由于端点可能包含敏感信息,我们应该仔细考虑何时公开它们。下表显示了内置端点的默认公开情况:
| ID | JMX | Web |
|---|---|---|
auditevents | Yes | No |
beans | Yes | No |
caches | Yes | No |
conditions | Yes | No |
configprops | Yes | No |
env | Yes | No |
flyway | Yes | No |
health | Yes | Yes |
heapdump | N/A | No |
httptrace | Yes | No |
info | Yes | No |
integrationgraph | Yes | No |
jolokia | N/A | No |
logfile | N/A | No |
loggers | Yes | No |
liquibase | Yes | No |
metrics | Yes | No |
mappings | Yes | No |
prometheus | N/A | No |
quartz | Yes | No |
scheduledtasks | Yes | No |
sessions | Yes | No |
shutdown | Yes | No |
startup | Yes | No |
threaddump | Yes | No |
如果想要更改公开的端点,可以使用以下特定技术的 include和exclude配置属性:
| Property | Default |
|---|---|
management.endpoints.jmx.exposure.exclude | |
management.endpoints.jmx.exposure.include | * |
management.endpoints.web.exposure.exclude | |
management.endpoints.web.exposure.include | health |
include 属性列出需要公开的端点 ID。exclude 属性列出不应公开的端点 ID,exclude 优先于 include。我们还可以使用端点 ID 列表来配置 include 和 exclude 属性。
应用程序信息(Application Information)公开了 ApplicationContext 中定义的所有 InfoContributor bean 收集的各种信息。 Spring Boot 包含许多自动配置的 InfoContributor bean,我们也可以编写自己的 InfoContributor bean。
在适当的时候,Spring Boot 会自动配置以下的 InfoContributor bean:
| ID | Bean | 描述 | 先决条件 |
|---|---|---|---|
build | BuildInfoContributor (opens new window) | 公开构建信息 | 资源文件META-INF/build-info.properties 存在 |
env | EnvironmentInfoContributor (opens new window) | 公开所有以 info.开头的环境属性 | 无 |
git | GitInfoContributor (opens new window) | 公开 git 信息 | 资源文件git.properties 存在 |
java | JavaInfoContributor (opens new window) | 公开 Java 运行时信息 | 无 |
os | OsInfoContributor (opens new window) | 公开操作系统信息 | 无 |
management.info.<id>.enabled 属性控制单个 InfoContributor bean 是否启用,不同的 InfoContributor bean 对此属性有不同的默认值,这取决于它们的先决条件和它们公开信息的性质。默认情况下 env、java 和 os 被禁用,我们可以通过将其 management.info.<id>.enabled 属性设置为 true 来开启。build 和 git 默认是开启的,我们可以通过将其 management.info.<id>.enabled 属性设置为 false 来禁用。
健康信息(Health Information)可以用来检查正在运行的应用程序状态。当生产系统出现故障时,监控软件经常使用它来提醒某人。
健康信息是从 HealthContributorRegistry 的内容中收集的(默认情况下,所有在 ApplicationContext 中定义的 HealthContributor 实例)。 Spring Boot 包含许多自动配置的 HealthContributor,我们也可以编写自己的。
在适当的时候,Spring Boot 会自动配置以下的 HealthIndicator bean:
我们可以通过 management.health.<key>.enabled 配置来启用或禁用选定的健康检查。
# Spring Boot Admin 介绍
Spring Boot Admin 是一个用于管理和监控我们 Spring Boot 应用程序的开源项目,由服务端(Spring Boot Admin Server)和客户端(Spring Boot Admin Client)两部分构成。
应用程序使用 Spring Boot Admin Client(通过 HTTP)或使用 Spring Cloud 自动发现(例如 Eureka、Consul、Nacos 等)向 Spring Boot Admin Server 注册。
Spring Boot Admin Server UI 是构建在 Spring Boot Actuator 端点之上的 Vue.js 应用程序,Spring Boot Admin Server 的监控信息均来自 Spring Boot Actuator 端点,并且通过端点来管理我们的应用程序。
# 构建 Spring Boot Admin Server
- 使用 Spring Initializr (opens new window) 初始化一个 Spring Boot 项目,并加入以下依赖和仓库:
<dependency>
<groupId>de.codecentric</groupId>
<artifactId>spring-boot-admin-starter-server</artifactId>
<version>3.0.0-M1</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-security</artifactId>
</dependency>
<repositories>
<repository>
<id>spring-milestone</id>
<snapshots>
<enabled>false</enabled>
</snapshots>
<url>http://repo.spring.io/milestone</url>
</repository>
<repository>
<id>spring-snapshot</id>
<snapshots>
<enabled>true</enabled>
</snapshots>
<url>http://repo.spring.io/snapshot</url>
</repository>
<repository>
<id>sonatype-nexus-snapshots</id>
<name>Sonatype Nexus Snapshots</name>
<url>https://oss.sonatype.org/content/repositories/snapshots/</url>
<snapshots>
<enabled>true</enabled>
</snapshots>
<releases>
<enabled>false</enabled>
</releases>
</repository>
</repositories>
- 在 application.properties 配置文件中添加 Spring Security 用户名、密码的配置属性,用于登录 Spring Boot Admin Server:
spring.security.user.name=novel
spring.security.user.password=novel
- 在启动类上添加 @EnableAdminServer 注解:
@SpringBootApplication
@EnableAdminServer
public class MonitorApplication {
public static void main(String[] args) {
SpringApplication.run(MonitorApplication.class, args);
}
}
- 添加 Spring Security 配置类:
/**
* Spring Security 配置
*
* @author xiongxiaoyang
* @date 2022/6/8
*/
@Configuration(proxyBeanMethods = false)
public class SecuritySecureConfig extends WebSecurityConfigurerAdapter {
private final AdminServerProperties adminServer;
private final SecurityProperties security;
public SecuritySecureConfig(AdminServerProperties adminServer, SecurityProperties security) {
this.adminServer = adminServer;
this.security = security;
}
@Override
protected void configure(HttpSecurity http) throws Exception {
SavedRequestAwareAuthenticationSuccessHandler successHandler = new SavedRequestAwareAuthenticationSuccessHandler();
successHandler.setTargetUrlParameter("redirectTo");
successHandler.setDefaultTargetUrl(this.adminServer.path("/"));
http.authorizeRequests(
authorizeRequests -> authorizeRequests
.antMatchers(this.adminServer.path("/assets/**")).permitAll()
.antMatchers(this.adminServer.path("/actuator/info")).permitAll()
.antMatchers(this.adminServer.path("/actuator/health")).permitAll()
.antMatchers(this.adminServer.path("/login")).permitAll()
.anyRequest().authenticated()
).formLogin(
formLogin -> formLogin
.loginPage(this.adminServer.path("/login"))
.successHandler(successHandler).and()
).logout(
logout -> logout.logoutUrl(this.adminServer.path("/logout"))
).httpBasic(Customizer.withDefaults())
.csrf(csrf -> csrf.csrfTokenRepository(CookieCsrfTokenRepository.withHttpOnlyFalse())
.ignoringRequestMatchers(
new AntPathRequestMatcher(this.adminServer.path("/instances"),
HttpMethod.POST.toString()),
new AntPathRequestMatcher(this.adminServer.path("/instances/*"),
HttpMethod.DELETE.toString()),
new AntPathRequestMatcher(this.adminServer.path("/actuator/**"))
))
.rememberMe(rememberMe -> rememberMe
.key(UUID.randomUUID().toString())
.tokenValiditySeconds(1209600));
}
/**
* Required to provide UserDetailsService for "remember functionality"
* */
@Override
protected void configure(AuthenticationManagerBuilder auth) throws Exception {
auth.inMemoryAuthentication().withUser(security.getUser().getName())
.password("{noop}" + security.getUser().getPassword()).roles("USER");
}
}
此时,运行应用程序,浏览器中访问 8080 端口,输入上面配置的用户名和密码即可进入 Spring Boot Admin Server 控制台管理和监控我们的应用程序。
# 通过 Spring Boot Admin Client 注册 novel 服务
- 在我们 novel 项目中加入以下依赖和仓库:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>de.codecentric</groupId>
<artifactId>spring-boot-admin-starter-client</artifactId>
<version>3.0.0-M1</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-security</artifactId>
</dependency>
<repository>
<id>sonatype-nexus-snapshots</id>
<name>Sonatype Nexus Snapshots</name>
<url>https://oss.sonatype.org/content/repositories/snapshots/</url>
<snapshots>
<enabled>true</enabled>
</snapshots>
<releases>
<enabled>false</enabled>
</releases>
</repository>
- 在 novel 项目的 application.yml 配置文件中加入以下配置:
spring:
# Spring Boot 应用管理和监控
boot:
admin:
client:
# 是否开启 Spring Boot Admin 客户端
enabled: true
# Spring Boot Admin 服务端注册地址
url: http://localhost:8080
# Spring Boot Admin 服务端认证用户名
username: novel
# Spring Boot Admin 服务端认证密码
password: novel
instance:
metadata:
# SBA Client
user.name: ${spring.security.user.name}
user.password: ${spring.security.user.password}
security:
user:
# Actuator 端点保护配置
name: ENDPOINT_ADMIN
password: ENDPOINT_ADMIN
roles: ENDPOINT_ADMIN
# Actuator 端点管理
management:
# 端点公开配置
endpoints:
# 通过 HTTP 公开的 Web 端点
web:
exposure:
# 公开所有的 Web 端点
include: "*"
# 端点启用配置
endpoint:
logfile:
# 启用返回日志文件内容的端点
enabled: true
# 外部日志文件路径
external-file: logs/novel.log
info:
env:
# 公开所有以 info. 开头的环境属性
enabled: true
health:
rabbit:
# 关闭 rabbitmq 的健康检查
enabled: false
elasticsearch:
# 关闭 elasticsearch 的健康检查
enabled: false
- novel 项目启动类中添加 Spring Boot Actuator 端点保护的 Spring Security 配置:
@Bean
public SecurityFilterChain securityFilterChain(HttpSecurity http) throws Exception {
http.csrf().disable()
.requestMatcher(EndpointRequest.toAnyEndpoint())
.authorizeRequests(requests -> requests.anyRequest().hasRole("ENDPOINT_ADMIN"));
http.httpBasic();
return http.build();
}
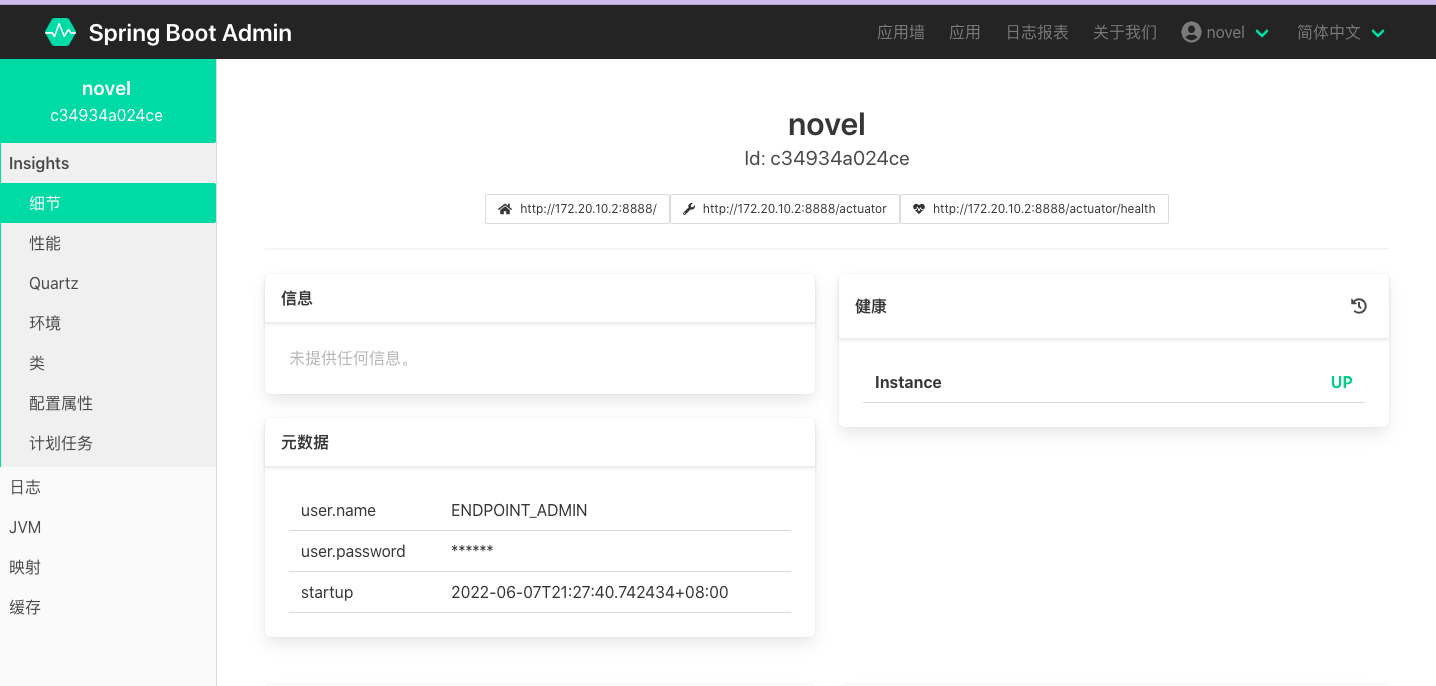
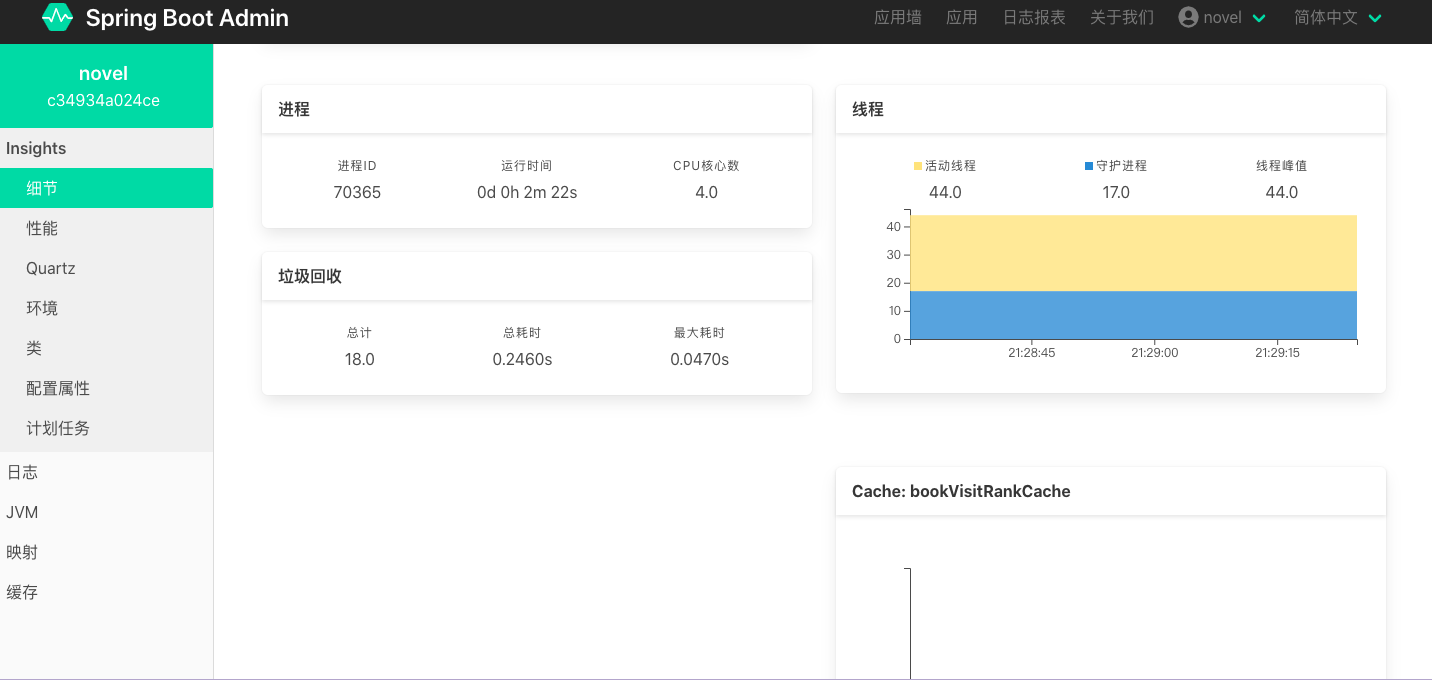
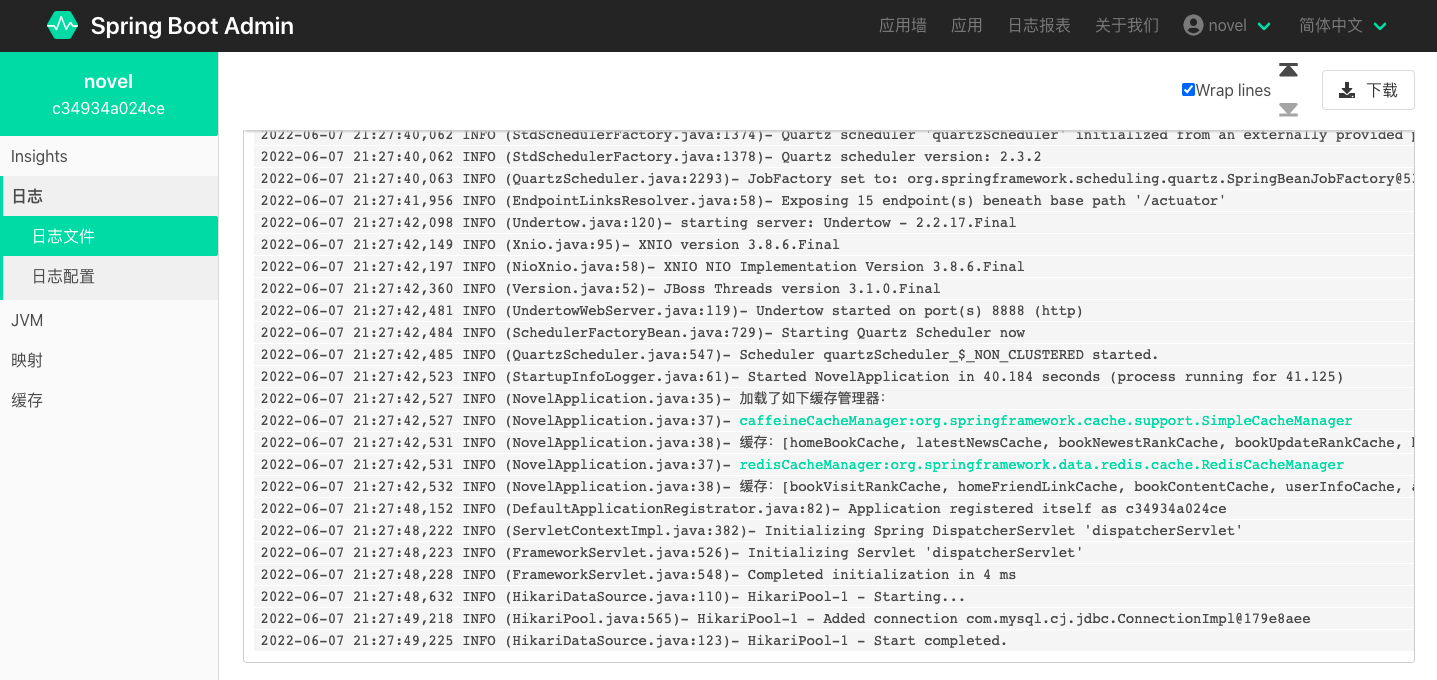
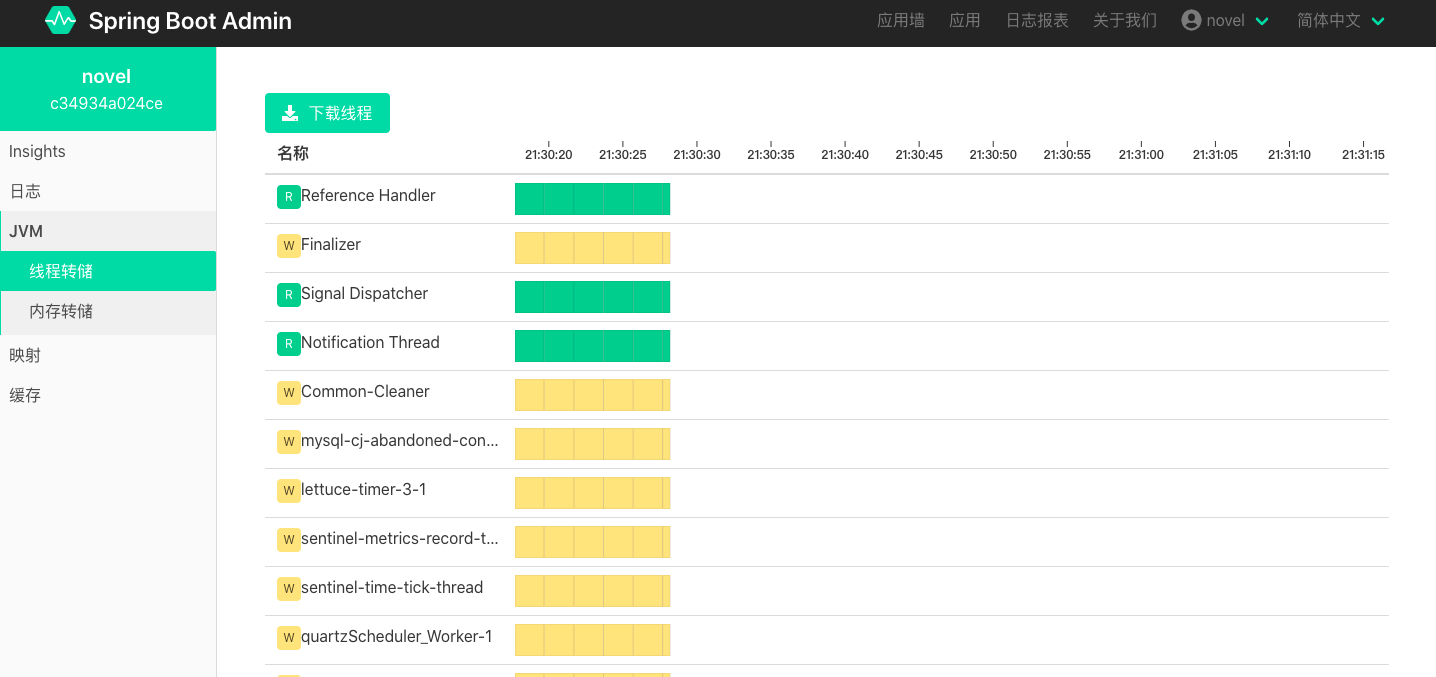
此时,启动 novel 项目,登录 Spring Boot Admin Server 控制台可以看到如下监控信息:
踩坑:在启动 Spring Boot Admin Server 之前有个 node 程序监听了 8080 端口没有释放,然后启动 Spring Boot Admin Server(默认也是 8080 端口),此时浏览器中可以正常访问到 Spring Boot Admin Server 的界面,但是 novel 服务无法注册到 Spring Boot Admin Server 上,提示404 错误。后来发现 novel 服务的注册被监听 8080 端口的 node 程序处理了,关闭该 node 程序即可正常注册。 该机制请参考 Node.Js 的端口重用 (opens new window)。